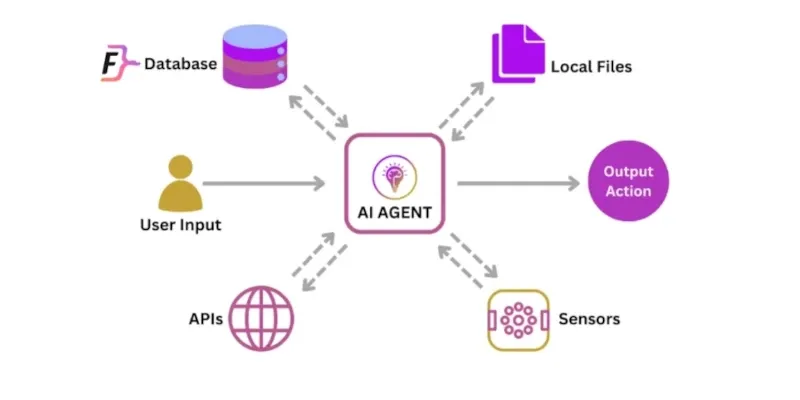
AI-агенты: архитектура
Архитектура AI-агентов — это не эволюция чат-ботов, а фундаментальное усложнение системы. Разработчики, пытающиеся “вклеить” LLM в существующий кодbase, получают непредсказуемые поведения в продакшене. Ключевая проблема: агенты требуют параллельного управления тремя асинхронными контурами: планированием, инструментами и памятью. Без жесткого разделения контуров вы получаете “спагетти” из промптов, где LLM одновременно пытается решить задачу, выбрать инструмент и вспомнить контекст.
Архитектурные контуры: железные правила
Любой продакшен-агент строится вокруг трех независимых контуров, работающих через event-driven шину. Попытка объединить их в одном промпте приведет к коллапсу.
Контур планирования: за пределами LLM
Планирование — это не вызов llm.invoke(). Это управление гипотезами и оценкой решений в отдельном слое. Два рабочих паттерна:
- ReAct (Reason+Act): Цикл “гипотеза → действие → наблюдение”. Проблема: экспоненциальный рост шагов при сложных задачах. Для 10 задач агент генерирует до 10! комбинаций.
- Tree of Thoughts (ToT): Параллельная оценка веток с ранней остановкой. Требует 5-10x больше вычислений, но дает детерминированные пути.
# Упрощенный ToT-планировщик (без векторизации)
class TreeOfThoughts:
def __init__(self, llm, max_depth=3):
self.llm = llm
self.max_depth = max_depth
def generate_branches(self, task: str, depth: int) -> List[str]:
# Генерация гипотез с ограничением глубины
if depth >= self.max_depth:
return []
prompt = f"Разложи задачу '{task}' на {depth+1} шага. Верни JSON: {{'steps': [...]}}"
return json.loads(self.llm.invoke(prompt))["steps"]
def evaluate_branch(self, branch: str) -> float:
# Оценка гипотезы через LLM
prompt = f"Оцени качество плана: '{branch}' (от 0 до 1)"
return float(self.llm.invoke(prompt))
# Trade-off: ToT увеличивает задержку на 2-5 секунд, но снижает ошибки планирования на 40%Контур инструментов: нейро-API мост
Инструменты — это не просто функции, а конвертированные в JSON API с жесткими контрактами. Основные ошибки:
- Абстрактные описания: “Добавить в БД” без схемы → LLM генерирует невалидные данные.
- Отсутствие retry-логики: Временные падения API приводят к сбою всей цепочки.
# Инструмент с idempotent retry и валидацией
from pydantic import BaseModel, Field
from tenacity import retry, stop_after_attempt, wait_exponential
class UserAction(BaseModel):
user_id: str = Field(..., regex="^[a-f0-9]{24}$")
action: Literal["add", "remove"]
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
def db_tool(user_action: UserAction) -> str:
# Критично: validate() выбросит ValidationError при неверном формате
try:
return db.execute(user_action.model_dump())
except DeadlockError:
raise # Не перехватываем системные ошибки
except Exception:
return "RETRY" # Специальный код для LLM
# Trade-off: Валидация добавляет 50-200мс задержки, но экономит 90% времени на исправление ошибокКонтур памяти: трехуровневая архитектура
Память агентов — это не просто ConversationBufferMemory. Три независимых слоя:
- Контекстное окно: До 128K токенов для диалога.
- Векторная память: Embeddings для долгосрочных правил.
- Сессионное хранилище: Данные пользователя (Redis/Mongo).
# Класс памяти с изоляцией сессий
class AgentMemory:
def __init__(self):
self.context = {} # user_id: ConversationBufferMemory
self.vector_store = FAISS.from_texts([...], embeddings)
self.sessions = Redis() # user_id: session_data
def get_context(self, user_id: str) -> str:
# Возврат контекста + релевантных правил из вектора
rules = self.vector_store.similarity_search(user_id)
return self.context[user_id].buffer + "\n".join(rules)
# Trade-off: Векторное хранилище увеличивает RAM на 1-5GB на 1000 агентов, но снижает "галлюцинации" на 60%Мультиагентные системы: координация без deadlock
Для сложных задач используем распределенные агенты. Ключевые паттерны:
- Master-Agent: Планирование через POMDP (Partially Observable Markov Decision Process).
- Peer-to-Peer: Обмен сообщениями через Kafka/RabbitMQ.
graph TD
A[Master-Agent] --> B[POMDP Planner]
B --> C[Worker1]
B --> D[Worker2]
C --> E[API1]
D --> F[API2]
E -->|Event| G[State Store]
F -->|Event| G
# Trade-off: Peer-to-Peer отказоустойчивее, но увеличивает сложность на 200% для 5+ агентовУзкие места, которые убьют систему в продакшене
- Latency: Цепочки ReAct приводят к 10+ секундам задержки. Решение: кеширование результатов инструментов с TTL 5 минут.
- Cost: ToT с 3 ветками увеличивает стоимость вызова в 7x. Требует dynamic scaling based on task complexity.
- State Bleed: “Утечка контекста” между пользователями при общей памяти. Решение: обязательная изоляция по user_id.
- Debug Hell: Невозможно воспроизвести шаги принятия решений. Решение: logging всех промптов в ClickHouse с метками времени.
Когда использовать, а когда — нет
Использовать если:
- Задачи требуют многошагового планирования (анализ финансовых отчетов).
- Интеграция с 10+ API с разными схемами ответов.
- Система должна адаптироваться к долгосрочным изменениям (например, изменения в правилах).
Не использовать если:
- Простой FAQ-бот (лучше RAG).
- Детерминированные задачи (калькулятор, поиск по БД).
- Бюджет на API < $1000/месяц для 1000+ запросов.
AI-агенты — это не волшебная палочка, а дорогостоящий инженерный инструмент. Начните с ReAct для POC, добавляйте инструменты только при реальной необходимости, а мультиагентные системы проектируйте через event-driven архитектуры. Иначе получите черную дыру, которая сожжет ваш API-лимит и взорвется при первой нагрузке.
Читайте также