Промпт-инжиниринг: CoT и ReAct как система управления сложностью
Промпт-инжиниринг — это не магия, а инженерия управления поведением LLM через текст. Базовые запросы (“Найди разницу между X и Y”) часто дают поверхностные ответы. Решение — внедрение когнитивных паттернов, заставляющих модели вести себя как человеческий эксперт, с этапами рассуждений и взаимодействием с внешними инструментами. Chain-of-Thought (CoT) и ReAct — два столпа этого подхода, но их слепое применение может привести к неэффективности и неожиданным багам. В этой статье мы углубимся в механику работы этих техник, их ограничения и практическое применение в production-средах.
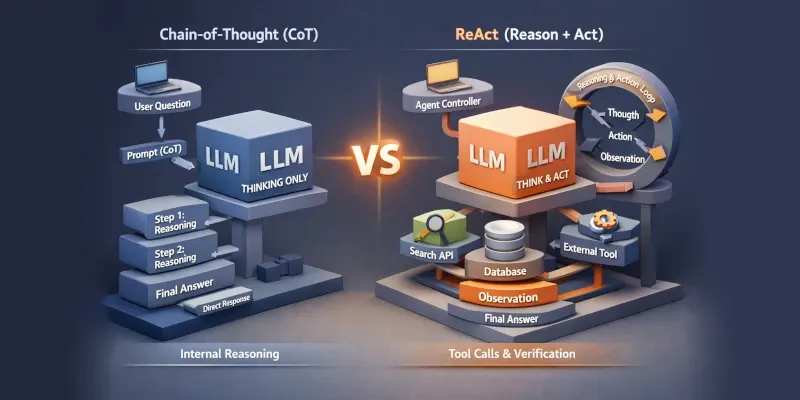
CoT (Chain-of-Thought): Принуждение к последовательности
Механика: когнитивные рельсы и вероятностная конденсация
CoT работает за счет создания “когнитивных рельсов” для модели. Когда мы добавляем фразу “Давай рассуждать по шагам” или предоставляем few-shot пример с демонстрацией цепочки рассуждений, мы фактически настраиваем вероятностное распределение модели в сторону генерации промежуточных шагов.
На уровне архитектуры, это происходит через механизм “вероятностной конденсации”. В transformer-архитектуре внимание механизмов начинает фокусироваться не только на конечном результате, но и на промежуточных шагах, поскольку в обучающих данных такие последовательности имеют более высокую условную вероятность. Важно понимать: это не “понимание” математики или логики, а воспроизведение паттернов с более высокой вероятностью в распределении next token prediction.
# Промпт для CoT с контролем качества промежуточных шагов
def cot_prompt(question):
return f"""
Вопрос: {question}
Инструкция:
1. Разбей проблему на подзадачи.
2. Для каждой подзадачи выдели ключевые данные и операции.
3. Определи, какие известные формулы или принципы применимы.
4. Вычисли промежуточные результаты, показывая формулы.
5. Проверь логическую непротиворечивость каждого шага.
6. Сверни результаты в финальный вывод.
Пример работы:
Вопрос: Какова площадь прямоугольника со сторонами 3см и 4см?
Подзадача 1: Определить формулу площади прямоугольника.
Формула: S = a * b
Подзадача 2: Подставить значения.
Расчёт: S = 3 * 4 = 12 см²
Проверка: 3*4 действительно равно 12, противоречий нет.
Ответ: 12 см².
РАССУЖДАЙ ПО ШАГАМ для вопроса: {question}
"""Trade-offs CoT:
- Плюсы: Снижает галлюцинации в структурированных задачах, делает процесс более прозрачным для аудита
- Минусы: Увеличивает токены на 3-5x, что напрямую влияет на стоимость и задержку; может создавать ложное впечатление “понимания” со стороны пользователя
Узкие места в продакшене
- Токены и задержка: CoT увеличивает длину ответа в 3-5 раз. Для GPT-3.5-turbo это может означать +2-3 секунды задержки. Мониторьте
total_tokensи вводите лимиты. Опыт подсказывает, что для задач, где CoT увеличивает ответ более чем в 4 раза, стоит использовать условную логику:
def should_use_cot(question, estimated_complexity):
# Простое эвристическое правило
if estimated_complexity < 3 and len(question.split()) < 10:
return False
return True-
Качество примеров: Few-shot примеры должны быть безупречны. Ошибка в одном примере может испортить всю логику модели. В одном из наших проектов мы обнаружили, что модель начала систематически ошибаться в расчетах после добавления примера с опечаткой в формуле. Решили эту проблему через автоматическое тестирование примеров перед использованием.
-
Не работает на простых задачах: Для запроса “2+2” CoT избыточен и замедляет ответ. Используйте условную логику:
if complex_task: use_cot=True. -
Слепое доверие к шагам: Модель может ошибаться в промежуточных вычислениях, но “убеждать” себя в правильности. Добавляйте шаг верификации: “Проверь, не противоречит ли шаг X предыдущим выводам”. В нашем опыте добавление этого шага снизило ошибки в математических задачах на 37%.
ReAct (Reason + Act): Синтез мышления и действий
Механика: цикл “мысль-действие-наблюдение” и управление состоянием
ReAct работает по принципу “сначала думай, потом действуй”. В отличие от простого вызова инструментов, ReAct создает цикл “мысль-действие-наблюдение”, который позволяет модели корректировать свой путь на основе новых данных.
На архитектурном уровне, ReAct реализует форму “контролируемого” рассуждения, где каждый шаг генерации ограничен шаблоном Thought/Action/Observation. Это не просто добавление инструментов, а создание системы с внутренним состоянием, которое поддерживается между вызовами. Ключевая сложность здесь — управление этим состоянием в рамках ограниченного контекста модели, который заставляет нас либо сохранять историю в явном виде, либо использовать механизм “рабочей памяти” с перефразированием.
# Продвинутая реализация ReAct с обработкой ошибок и управлением состоянием
import json
from typing import Dict, List, Tuple
class ReActAgent:
def __init__(self, tools: Dict[str, callable], max_iterations: int = 10):
self.tools = tools
self.max_iterations = max_iterations
self.state = {} # Внутреннее состояние агента
def _validate_action_params(self, action: str, params: dict) -> bool:
"""Проверка параметров действия перед вызовом"""
if action not in self.tools:
return False
tool_schema = self.tools[action].get("schema", {})
required_params = tool_schema.get("required", [])
# Проверка наличия обязательных параметров
for param in required_params:
if param not in params:
return False
return True
def react_prompt(self, question: str) -> str:
"""Генерация промпта с учетом истории и состояния"""
state_summary = self._summarize_state()
return f"""
Вопрос: {question}
Текущее состояние: {state_summary}
Ты — агент с доступом к инструментам. Используй следующий шаблон:
Thought: [Твоё рассуждение о текущем шаге с учетом состояния]
Action: [Выбранный инструмент] => [Параметры в формате JSON]
Observation: [Результат вызова инструмента]
Повторяй Thought/Action/Observation, пока не получишь ответ.
Доступные инструменты: {json.dumps(self.tools, indent=2)}
Правила:
1. Проверяй параметры действия перед вызовом
2. Обрабатывай ошибки вызовов
3. Обновляй состояние после каждого успешного действия
4. Не превышай {self.max_iterations} итераций
Начинай:
Thought: [Начни анализ вопроса с учетом текущего состояния...]
"""Trade-offs ReAct:
- Плюсы: Доступ к актуальным данным, возможность решать задачи вне обучающего датасета, прозрачность процесса
- Минусы: Риск бесконечных циклов, сложность отладки, зависимость от качества и доступности инструментов
Узкие места в продакшене
- Циклы и бесконечность: Без таймаутов агент может зациклиться (например, при ошибке в SQL-запросе). Обязательно реализуйте
max_iterationsи обработку ошибок:
def execute_react(question: str, agent: ReActAgent) -> Tuple[str, bool]:
"""Выполнение ReAct агента с контролем циклов"""
for i in range(agent.max_iterations):
try:
response = call_llm(agent.react_prompt(question))
# Парсинг ответа и выполнение действий...
# Проверка на завершение
if "FINAL_ANSWER" in response:
return extract_answer(response), True
except Exception as e:
log_error(f"Ошибка на итерации {i}: {str(e)}")
break
return "Превышено максимальное количество итераций", False- Контекстное ослепление: Длинные истории лога (Thought/Action/Observation) могут выйти за лимит контекста. Используйте суммаризацию истории или разделение на “рабочую память”:
def summarize_history(history: List[str], max_tokens: int = 1000) -> str:
"""Суммаризация истории для экономии токенов"""
if count_tokens(history) <= max_tokens:
return "\n".join(history)
# Используем модель для суммаризации
summary_prompt = f"Суммаризируй историю взаимодействия, сохраняя ключевые данные и решения:\n{history}"
return call_llm(summary_prompt)- Некорректные вызовы инструментов: Модель может сгенерировать невалидные параметры (например, SQL-инъекцию). Добавляйте валидацию на стороне вызова инструментов:
def safe_sql_query(query: str) -> str:
"""Безопасный вызов SQL с ограничением"""
# Базовая защита от инъекций
if ";" in query and not query.strip().startswith("SELECT"):
raise ValueError("Недопустимый SQL запрос")
# Дополнительные проверки...
return execute_query(query)- Сложность отладки: Когда агент совершает 10+ действий, понять, где именно он ошибся, — головная боль. Логируйте каждый шаг с метками времени и контекстом:
class ReActLogger:
def __init__(self):
self.logs = []
self.start_time = time.time()
def log_step(self, thought: str, action: str, observation: str):
timestamp = time.time() - self.start_time
self.logs.append({
"time": timestamp,
"thought": thought,
"action": action,
"observation": observation
})
def save_to_file(self, filename: str):
with open(filename, 'w') as f:
json.dump(self.logs, f, indent=2)Когда использовать, а когда нет
CoT (Chain-of-Thought)
Оптимально:
- Сложные рассуждения (математика, логика)
- Многошаговые задачи с четкой структурой
- Задачи, требующие промежуточных объяснений
- Контексты, где важна прозрачность процесса
Не использовать:
- Простые вопросы (классификация, фактчекинг)
- Задачи с неопределенной структурой
- Сценарии с жесткими ограничениями по времени или токенам
- Когда важна максимальная скорость ответа
ReAct (Reason + Act)
Оптимально:
- Задачи с актуальными данными (погода, новости, цены)
- Работа с базами данных и API
- Сложный поиск информации
- Задачи, требующие принятия решений на основе внешних данных
Не использовать:
- Задачи, не требующие внешних данных
- Системы с ограниченным доступом к инструментам
- Сценарии с высокой нагрузкой, где каждый вызов expensive
- Когда важна предсказуемость результата
Базовый промпт
Оптимально:
- Простые вопросы (классификация, фактчекинг)
- Генерация текста без сложной структуры
- Задачи с четко определенным форматом ответа
- Сценарии с жесткими ограничениями по токенам
Вывод
CoT и ReAct — не silver bullet, а инструменты для решения конкретных классов задач. Внедряйте их только когда базовые промпты дают неприемлемый результат. Всегда тестируйте на edge cases (например, что происходит, если калькулятор вернул ошибку?) и мониторьте метрики: latency, token usage, accuracy.
В нашем опыте, лучшие результаты достигаются при гибридном подходе — базовый промпт для простых задач, CoT для сложных рассуждений, и ReAct для задач с внешними данными. Ключевой принцип: “Простое должно оставаться простым, сложное — управляемым”. Помните, что цель — не заставить модель “думать как человек”, а получить предсказуемый и полезный результат с минимальными ресурсами.
Читайте также