AI-агенты в продакшене
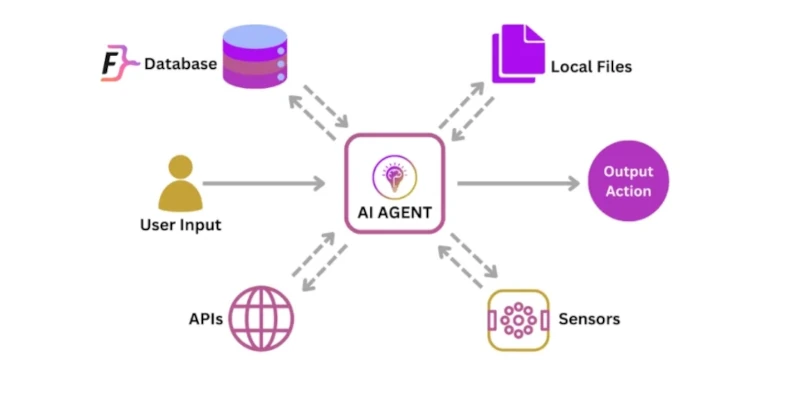
В продакшене AI-агенты ведут себя совершенно иначе, чем традиционное ПО. Их решения непредсказуемы, а поведение меняется в зависимости от контекста, входных данных и даже времени суток. Без правильного мониторинга и логирования вы слепы: не понимаете, почему агент принял то или иное решение, и не можете отследить деградацию качества. Стандартные подходы к мониторингу здесь не работают — нужны специализированные системы, учитывающие специфику ИИ-систем.
AI-агенты в продакшене: вызовы и решения
Особенности работы AI-агентов и их последствия для мониторинга
В отличие от детерминированных систем, где один и тот же вход всегда дает один и тот же выход, AI-агенты работают с вероятностными моделями. Их решения могут быть правильными в 99% случаев, но именно те 1% обходятся вам дорого. Основные проблемы:
- Непрозрачность решений: Черный ящик моделей делает отладку сложной задачей. Когда агент ошибается, вы не сразу понимаете причину.
- Дрейф данных: Со временем распределение входных данных меняется, и модель начинает терять точность без обновления кода.
- Каскадные сбои: Ошибка одного агента может повлиять на работу других, создавая цепную реакцию.
- Изменчивость поведения: Агент может работать стабильно месяцами, а затем внезапно начать проявлять аномальное поведение.
Архитектура системы мониторинга для AI-агентов
Для AI-агентов нужна многоуровневая система мониторинга, отслеживающая как технические метрики, так и качество принятия решений:
- Базовый инфраструктурный мониторинг: CPU, GPU, память, сеть — как и для любого приложения.
- Метрики качества модели: Точность, precision, recall, F1-score, логарифмическая потеря.
- Метрики бизнес-показателей: Конверсии, удержание пользователей, выручка — то, что действительно важно для бизнеса.
- Метрики принятия решений: Распределение по категориям решений, частота редких событий, отклонения от ожидаемого поведения.
- Метрики обратной связи: Отметки пользователей, ручные проверки, данные о корректировках.
Особенность AI-мониторинга — необходимость отслеживать не только текущие значения, но и их распределение во времени. Агент может работать стабильно, но постепенно смещать распределение решений в сторону нежелательных исходов.
Логирование AI-агентов: что отслеживать и как анализировать
Логирование для AI-агентов должно включать:
- Контекст каждого решения: Входные данные, метаданные времени и состояния системы.
- Промежуточные результаты: Веса модели, активации слоев, логиты перед финальным решением.
- Вероятности и неуверенность: Модель может быть уверена в правильности решения, но ошибаться, или наоборот — неуверенно угадать правильно.
- Историю взаимодействий: Если агент работает в среде с памятью, нужно отслеживать историю его действий и реакций среды.
Для анализа этих данных нужны специализированные инструменты:
- Лог-агрегация с поддержкой семантического поиска: Поиск по смыслу, а не по ключевым словам.
- Визуализация распределений: Графики, показывающие, как меняются решения со временем.
- Детекторы аномалий: Алгоритмы, автоматически обнаруживающие отклонения от нормы.
- Система A/B-тестирования: Сравнение производительности разных версий моделей и агентов.
Тестирование AI-агентов в продакшене
Тестирование AI-агентов в продакшене — это постоянный процесс, включающий:
- Канареечные релизы: Постепенное развертывание новых моделей для ограниченной группы пользователей.
- Адаптивное тестирование: Тестирование на данных, максимально приближенных к реальным, но безопасным.
- Человеческая валидация: Ручная проверка решений агента экспертами.
- Симуляции: Запуск агента в среде симуляций с различными сценариями.
import numpy as np
import logging
from typing import Dict, Any, Optional
from dataclasses import dataclass
from datetime import datetime
# Настройка логирования
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("ai_agent.log"),
logging.StreamHandler()
]
)
@dataclass
class DecisionContext:
"""Контекст принятия решения агентом"""
input_data: Dict[str, Any]
timestamp: datetime
model_version: str
confidence: float
decision: Any
class AIDecisionLogger:
"""Логгер для решений AI-агента"""
def __init__(self, agent_name: str, max_log_size: int = 10000):
self.agent_name = agent_name
self.decision_history = []
self.max_log_size = max_log_size
self.logger = logging.getLogger(agent_name)
def log_decision(self, context: DecisionContext, result: Any,
error: Optional[Exception] = None) -> None:
"""Логирование решения агента"""
log_entry = {
"agent": self.agent_name,
"timestamp": context.timestamp,
"input_data": context.input_data,
"model_version": context.model_version,
"confidence": context.confidence,
"decision": result,
"error": str(error) if error else None,
"metadata": {
"is_error": error is not None,
"decision_type": str(type(result))
}
}
self.decision_history.append(log_entry)
if len(self.decision_history) > self.max_log_size:
self.decision_history.pop(0)
if error:
self.logger.error(f"Decision error: {error}", extra={"decision": log_entry})
else:
self.logger.info(f"Decision made: {result}", extra={"decision": log_entry})
def get_anomaly_metrics(self, window_size: int = 100) -> Dict[str, float]:
"""Вычисление метрик для обнаружения аномалий"""
if len(self.decision_history) < window_size:
return {}
recent_decisions = self.decision_history[-window_size:]
# Распределение типов решений
decision_types = [d["decision_type"] for d in recent_decisions]
type_distribution = {t: decision_types.count(t)/window_size for t in set(decision_types)}
# Частота ошибок
error_rate = sum(1 for d in recent_decisions if d["metadata"]["is_error"]) / window_size
# Средняя уверенность
avg_confidence = np.mean([d["confidence"] for d in recent_decisions])
return {
"type_distribution": type_distribution,
"error_rate": error_rate,
"avg_confidence": avg_confidence
}
# Пример использования
if __name__ == "__main__":
# Инициализация логгера для AI-агента
agent_logger = AIDecisionLogger("recommender_agent")
# Симуляция работы агента
for i in range(5):
context = DecisionContext(
input_data={"user_id": f"user_{i}", "item_id": f"item_{i}"},
timestamp=datetime.now(),
model_version="v2.1",
confidence=0.95 - i*0.05,
decision="recommend"
)
try:
# Здесь должна быть логика принятия решения
if i == 3:
raise ValueError("Model prediction error")
agent_logger.log_decision(context, "item_rec_123")
except Exception as e:
agent_logger.log_decision(context, None, e)
# Получение метрик аномалий
metrics = agent_logger.get_anomaly_metrics()
print("Anomaly metrics:", metrics)Узкие места и компромиссы
При внедрении систем мониторинга для AI-агентов вы неизбежно столкнетесь с trade-offs:
-
Детализация логов vs. Производительность: Чем детальнее логирование, тем больше ресурсов оно потребляет. Для высоконагруженных систем это может стать узким местом.
-
Статистическая значимость vs. Задержки: Для точной оценки качества модели нужны данные с достаточным статистическим весом, но сбор таких данных может увеличивать задержки в системе.
-
Прозрачность vs. Конфиденциальность: Логирование входных данных и решений может нарушать конфиденциальность пользователей, особенно если данные содержат персональную информацию.
-
Автоматизация vs. Точность: Полностью автоматическая система мониторинга может пропускать сложные аномалии, требующие человеческого анализа.
-
Хранение данных vs. Стоимость: Детальные логи быстро растут в объеме, и их долговременное хранение может быть дорогостоящим.
Вывод: когда использовать AI-агенты в продакшене
AI-агенты — мощный инструмент, но не панацея. Они наиболее эффективны в сценариях:
- Где решение зависит от множества факторов и требует контекстного понимания
- Где есть возможность сбора обратной связи для непрерывного обучения
- Где гибкость и адаптивность важнее стопроцентной предсказуемости
- Где есть ресурсы на специализированную инфраструктуру мониторинга
В ситуациях, где предсказуемость важнее адаптивности, а ошибки критичны, классические алгоритмы или явно заданные правила могут оказаться более надежным решением. Всегда оценивайте trade-offs и не бойтесь отказываться от сложных AI-решений, если они не приносят реальной ценности по сравнению с более простыми альтернативами.
Читайте также