Квантование моделей: INT8, FP16, pruning
Когда глубокая модель с десятками миллионов параметров пытается работать на edge-устройстве с ограниченными ресурсами, она сталкивается с непростым выбором: остаться точной, но медленной или стать быстрой, но потерять качество. Квантование моделей — это не просто хитрость для уменьшения размера, а фундаментальное изменение представления весов, которое может ускорить инференс в 3-4 раза, уменьшить потребление памяти до 75% и иногда даже улучшить обобщение. Но за эти преимущества приходится платить точностью, а процесс квантирования — это не магия, а сложная оптимизация с множеством компромиссов.
Техническая суть квантования
Квантование — это процесс снижения точности чисел, представляющих веса модели. Вместо 32-битных чисел с плавающей запятой (FP32) мы используем 16-битные (FP16/BF16), 8-битные целые (INT8) или даже 4-битные (INT4) представления. Это не просто “обрезание” чисел — это сложный математический процесс, требующий перерасчета весов с минимизацией потери качества.
В основе лежит простой принцип: вместо хранения чисел в широком диапазоне с высокой точностью, мы используем более узкий диапазон с меньшей точностью. Например, INT8 может представлять числа от -128 до 127, что дает 256 возможных значений против ~4 миллиардов для FP32. Это позволяет:
- Сократить память в 4 раза (FP32 → INT8)
- Ускорить вычисления (целочисленные операции быстрее с плавающими на большинстве современных процессоров)
- Уменьшить энергопотребление
- Использовать специализированные инструкции (например, AVX-512 для INT8)
Но не все так просто. Прямое преобразование FP32 → INT8 без дополнительных шагов серьезно ухудшит качество модели. Здесь вступают в игру два ключ подхода: пост-тренировочное квантование (PTQ) и квантизация во время обучения (QAT).
Пост-тренировочное квантование (Post-Training Quantization, PTQ)
PTQ применяет квантизацию уже после завершения обучения модели. Это самый простой способ, но он может привести к значительному падению качества, особенно если модель плохо переносит потерю точности.
Процесс PTQ обычно включает:
- Калибровку: проход по части данных обучения для определения диапазона значений активаций
- Определение параметров квантизации: масштаба (scale) и нуля (zero-point) для каждого слоя
- Преобразование весов и активаций в целочисленный формат
- Тестирование качества на валидационном наборе
Важный момент: калибровочные данные должны быть репрезентативны для реального распределения входных данных, иначе квантизация будет неоптимальной.
import torch
import torch.quantization
def post_training_quantization(model, calib_loader):
# Устанавливаем модель в режим оценки
model.eval()
# Применяем квантизацию только для определенных слоев
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
# Объединяем слои для подготовки к квантизации
model_prepared = torch.quantization.prepare(model)
# Калибровка на части данных
with torch.no_grad():
for i, (data, _) in enumerate(calib_loader):
if i >= 100: # Используем только первые 100 батчей для калибровки
break
model_prepared(data)
# Применяем квантизацию
model_quantized = torch.quantization.convert(model_prepared)
return model_quantizedЭтот подход прост в реализации, но его эффективность сильно зависит от архитектуры модели и данных. Например, модели с нормализацией слоев (BatchNorm) часто лучше переносят квантизацию, так как нормализация помогает стабилизировать распределение активаций.
Квантизация во время обучения (Quantization-Aware Training, QAT)
QAT — это более сложный, но и более эффективный подход. Во время обучения мы симулируем эффекты квантизации, чтобы модель “училась” работать с пониженной точностью. Это делается путем вставки квантизационных модулей в архитектуру модели во время тренировки.
Ключевые особенности QAT:
- В процессе обучения веса остаются в FP32, но к ним применяются квантизационные операции с имитацией округления
- Используются “стратегические точки заморозки” (freeze points), где веса фиксируются перед квантованием
- Применяются техники динамического диапазона для адаптации к распределению данных
- Используется fine-tuning с малым learning rate для восстановления качества
import torch
import torch.quantization
def quantization_aware_training(model, train_loader, epochs=5):
# Копируем модель для работы
model_qat = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear, torch.nn.Conv2d},
dtype=torch.qint8
)
# Включаем режим QAT
model_qat.train()
model_qat.fuse_modules() # Объединяем слоев для лучшей производительности
# Оптимизатор
optimizer = torch.optim.Adam(model_qat.parameters(), lr=1e-4)
# Цикл обучения с QAT
for epoch in range(epochs):
for data, target in train_loader:
optimizer.zero_grad()
output = model_qat(data)
loss = torch.nn.functional.cross_entropy(output, target)
loss.backward()
optimizer.step()
# Переводим в режим инференса
model_qat.eval()
return model_qatОсновное преимущество QAT — лучшее сохранение качества модели после квантизации. Недостатки — сложность реализации и необходимость дообучения модели, что может занять значительное время.
Прагматический подход: от FP32 к INT8
На практике переход от FP32 к другим форматам часто происходит несколькими этапами:
-
FP16/BF16: Плавающая точность с 16 битами. Это первый шаг к квантизации, который часто применяется без существенной потери качества. Современные GPU (NVIDIA Tensor Core, AMD CDNA) имеют специализированные инструкции для ускорения операций FP16.
-
INT8: Целочисленная 8-битная квантизация. Здесь уже заметно падение точности, особенно в моделях с высокой чувствительностью к изменениям весов. Чтобы минимизировать потери, используются продвинутые техники:
- Периодическое уточнение квантизационных параметров
- Оптимизация группировки весов по их статистикам
- Использование техники “переноса диапазона” (range shifting) для оптимального использования доступных значений
-
INT4 и ниже: Экстремальная квантизация, которая может дать максимальное ускорение, но часто требует fine-tuning или даже дообучения всей модели. Этот подход оправдан только в случае крайней нехватки ресурсов.
Для большинства задач оптимальным балансом между производительностью и качеством является именно INT8. Вот практическая реализация:
import torch
import numpy as np
from torch.quantization import float_qparams_weight_only_quant
def int8_quantization_with_calibration(model, calib_dataset):
"""
Квантизация модели до INT8 с калибровкой
"""
# 1. Определяем калибровочные статистики
activation_stats = {}
def collect_stats(name):
def hook(module, input, output):
if isinstance(output, torch.Tensor):
activation_stats[name] = {
'min': output.min().item(),
'max': output.max().item(),
'mean': output.mean().item(),
'std': output.std().item()
}
return hook
# Регистрируем хуки для сбора статистики
for name, module in model.named_modules():
if isinstance(module, (torch.nn.Linear, torch.nn.Conv2d)):
module.register_forward_hook(collect_stats(name))
# Проходим по калибровочным данным
with torch.no_grad():
for data, _ in calib_dataset:
model(data)
# 2. Определяем параметры квантизации
quant_config = {}
for name, stats in activation_stats.items():
# Вычисляем scale и zero-point
qmin, qmax = -128, 127
min_val, max_val = stats['min'], stats['max']
# Расширяем диапазон на 5% для учета выбросов
min_val = min(min_val, 0) - 0.05 * abs(min_val)
max_val = max(max_val, 0) + 0.05 * abs(max_val)
scale = (max_val - min_val) / (qmax - qmin)
zero_point = qmin - round(min_val / scale)
zero_point = max(qmin, min(qmax, zero_point))
quant_config[name] = {
'scale': scale,
'zero_point': zero_point,
'min': min_val,
'max': max_val
}
# 3. Квантуем веса
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
# Получаем оригинальные веса
original_weight = module.weight.data
# Квантуем веса
qweight = torch.quantization.quantize_per_tensor(
original_weight,
quant_config[name]['scale'],
quant_config[name]['zero_point'],
torch.qint8
)
# Обновляем веса
module.weight.data = qweight
return model, quant_configЭтот код показывает, как калибровка помогает определить оптимальные параметры квантизации для каждого слоя, минимизируя потерю качества.
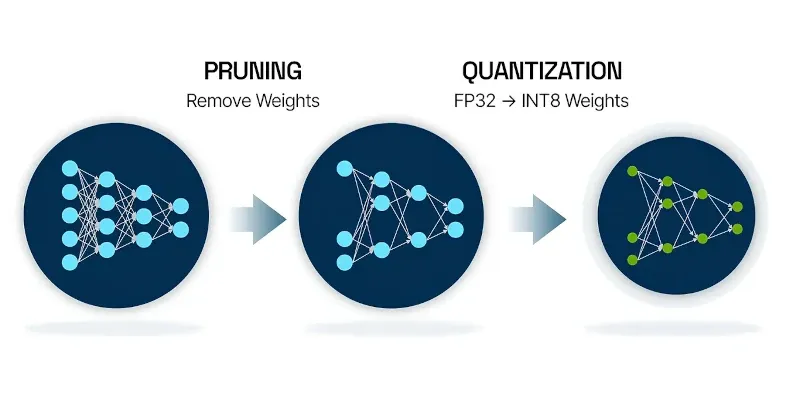
Методы Pruning: удаление избыточности
Квантование — не единственный способ оптимизации моделей. Pruning (обрезка) — это метод удаления ненужных весов или нейронов для создания разреженной модели. Существует несколько подходов к pruning:
- Structural pruning: Удаление целых нейронов или каналов, что сохраняет структуру модели
- Unstructured pruning: Удаление отдельных весов, что создает нерегулярную разреженность
- Magnitude-based pruning: Удаление весов с наименьшей абсолютной величиной
- Gradient-based pruning: Удаление весов, наименее влияющих на функцию потерь
Пример реализации magnitude-based pruning:
def magnitude_pruning(model, pruning_ratio=0.5):
"""
Применяет magnitude-based pruning к модели
pruning_ratio: доля весов, которые будут обнулены
"""
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
# Получаем веса
weight = module.weight.data
# Сортируем веса по абсолютной величине
sorted_abs_weight = torch.abs(weight).view(-1).sort()
# Определяем порог
threshold = sorted_abs_weight.values[int(len(sorted_abs_weight.values) * pruning_ratio)]
# Обнуляем веса, ниже порога
weight[torch.abs(weight) < threshold] = 0
# Обновляем веса
module.weight.data = weight
return modelPruning часто используется вместе с квантованием — сначала модель разреживается, а затем квантуется. Это позволяет достичь максимального эффекта сжатия.
Узкие места и компромиссы в продакшене
При внедрении квантизации в production необходимо учитывать ряд ограничений и проблем:
-
Потеря точности: Самое очевидное ограничение. Квантизация почти всегда приводит к некоторой потере качества, степень которой зависит от модели, данных и метода квантизации. В некоторых случаях потеря может быть критической (например, в медицинском или финансовом анализе).
-
Калибровочные данные: Для эффективной PTQ нужны репрезентативные данные, что не всегда возможно в реальных условиях. Если данные сильно отличаются от тех, на которых проводилась калибровка, качество модели может ухудшаться.
-
Аппаратное обеспечение: Не все устройства одинаково хорошо поддерживают разные форматы квантизации. INT8 хорошо поддерживается на современных CPU и GPU, но на embedded устройствах поддержка может быть ограничена.
-
Сложность развертывания: Квантованные модели требуют специальной инфраструктуры для инференса. Например, для INT8 нужны библиотеки с поддержкой квантованных операций (OpenVINO, TensorRT, ONNX Runtime).
-
Динамические диапазоны активаций: В некоторых моделях активации могут иметь очень разные диапазоны в разных слоях, что затрудняет применение единой стратегии квантизации.
-
Влияние на обучение: Если используется QAT, то процесс дообучения может быть нестабильным и требует тщательного подбора гиперпараметров.
-
Сериализация и совместимость: Квантованные модели имеют другую структуру, чем исходные, что может вызывать проблемы при деплое и миграции.
-
Версионирование и воспроизводимость: Квантизированные модели могут давать немного разные результаты в зависимости от версии библиотек и оборудования, что усложняет воспроизводимость экспериментов.
Когда стоит использовать квантование, а когда — нет
Квантование — не универсальное решение, а мощный инструмент, который стоит применять в определенных сценариях:
Использовать квантование, если:
- Работа на edge-устройствах: Когда модель должна работать на устройствах с ограниченными ресурсами (мобильные устройства, IoT-гаджеты).
- Низкая задержка (low-latency) приложения: В системах, где время отклика критично (автономные системы, робототехника).
- Масштабируемость: Когда нужно развернуть множество экземпляров модели и снизить стоимость инференса.
- Модели с избыточностью: Когда модель содержит много параметров, которые слабо влияют на результат (такие модели хорошо переносят pruning и квантование).
- Есть возможность дообучения: Когда можно провести fine-tuning модели после квантизации для восстановления качества.
Не использовать квантование, если:
- Критичная точность: Когда даже небольшое снижение качества неприемлемо (например, в системах безопасности, медицинском диагностике).
- Маленькие модели: Если модель уже достаточно компактна (например, меньше 1М параметров), преимущества квантизации могут быть незначительными.
- Нет ресурсов для калибровки/дообучения: Когда нет возможности собрать репрезентативные данные для калибровки или провести дообучение.
- Аппаратное обеспечение не поддерживает: Если целевое устройство не имеет аппаратной поддержки нужного формата квантизации.
- Модель очень чувствительна к изменениям: Некоторые архитектуры (например, с большим количеством внимания или регуляризации) могут нестабильно работать после квантизации.
Заключение
Квантование моделей — это не просто тренд, а фундаментальная техника, которая позволяет развертывать сложные ИИ-системы на ресурсоограниченных устройствах. INT8, FP16 и pruning дают мощные инструменты для оптимизации, но каждый из них имеет свои компромиссы.
Опыт показывает, что для большинства компьютерного зрения и NLP задач оптимальным путем является последовательное применение нескольких техник: сначала pruning для удаления избыточности, затем FP16/BF16 как первый шаг к квантизации, и наконец INT8 для максимального ускорения. Для особо чувствительных моделей QAT позволяет сохранить качество после квантизации, но требует дополнительных ресурсов на дообучение.
Ключ к успешной квантизации — это не просто применение техник, а глубокое понимание того, как они влияют на вашу конкретную модель в ваших конкретных условиях. Тестируйте, измеряйте, экспериментируйте и всегда помните: лучшая квантизация — это та, которая незаметна для пользователя, но заметно ускоряет ваш продукт.
Читайте также