Distillation: сжатие моделей
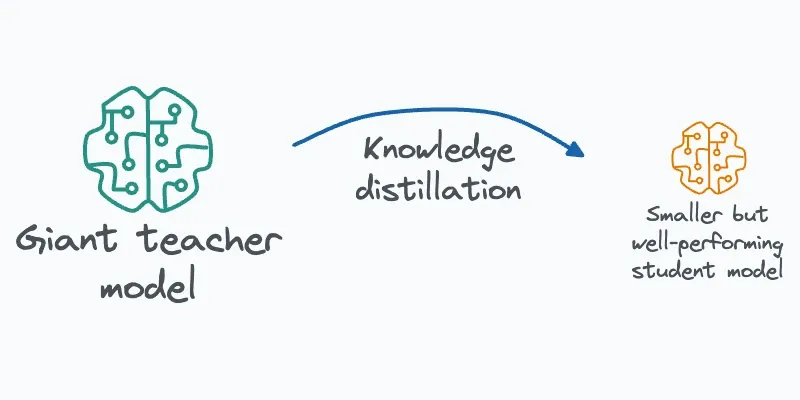
Distillation — это техника сжатия моделей, где большая и точная “учительская” модель обучает более компактную “ученическую”, сохраняя при этом значительную часть производительности. В эпоху развертывания моделей на мобильных устройствах и в IoT-устройствах, где ресурсы ограничены, этот подход становится не просто умным трюком, а необходимостью. Но как именно это работает и стоит ли применять его везде?
Учитель и ученик: механика передачи знаний
Distillation — это не просто fine-tuning маленькой модели на выходе большой. Здесь мы передаем не только правильные ответы (hard targets), но и “уверенность” модели-учителя (soft targets). Когда большая модель классифицирует изображение, она не просто говорит “это кошка с вероятностью 95%”, а распределение вероятностей по всем классам несет информацию о том, почему другие классы были отвергнуты. Эта информация бесценна для ученика.
В классическом обучении мы минимизируем cross-entropy между предсказаниями модели и one-hot метками. В distillation мы минимизируем cross-entropy между выходами ученика и “мягкими” метками от учителя (которые получаются через temperature scaling).
import torch
import torch.nn as nn
import torch.nn.functional as F
class DistillationLoss(nn.Module):
def __init__(self, temperature=5.0):
super().__init__()
self.temperature = temperature
def forward(self, student_logits, teacher_logits, targets):
# Soft targets от учителя с temperature
soft_teacher = F.softmax(teacher_logits / self.temperature, dim=1)
# Soft targets от ученика с temperature
soft_student = F.log_softmax(student_logits / self.temperature, dim=1)
# Distillation loss - KL дивергенция между мягкими распределениями
distillation_loss = F.kl_div(soft_student, soft_teacher, reduction='batchmean')
# Temperature^2 для компенсации scaling
distillation_loss *= (self.temperature ** 2)
# Если есть hard targets, добавляем обычный loss
if targets is not None:
hard_loss = F.cross_entropy(student_logits, targets)
# Веса можно настраивать
return 0.5 * distillation_loss + 0.5 * hard_loss
return distillation_lossTemperature — это ключевой гиперпараметр. При T > 1 распределение становится более “размытым”, что помогает ученику учиться более общим признакам. При T < 1 распределение становится более “острым”, что может быть полезно на финальных этапах обучения.
Архитектурные соображения
Выбор архитектуры ученика — это не всегда просто уменьшение слоев. Иногда эффективнее менять сам тип слоев:
class EfficientStudent(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
# Замена сверток на depthwise-separable свертки
self.features = nn.Sequential(
# Первые слобы оставляем как есть для сохранения основных признаков
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
# Depthwise-separable свертки для экономии параметров
nn.Conv2d(32, 32, kernel_size=3, padding=1, groups=32),
nn.Conv2d(32, 64, kernel_size=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Добавляем attention механизмы для компенсации уменьшения сложности
ChannelAttention(64),
# Остальные слои...
)
self.classifier = nn.Linear(512, num_classes)
def forward(self, x):
x = self.features(x)
x = nn.AdaptiveAvgPool2d((1, 1))(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
class ChannelAttention(nn.Module):
def __init__(self, channels, reduction_ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(channels, channels // reduction_ratio, 1),
nn.ReLU(),
nn.Conv2d(channels // reduction_ratio, channels, 1)
)
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return torch.sigmoid(out) * xТакая архитектура позволяет сократить количество параметров в 5-10 раз по сравнению с оригинальной моделью, сохранив при этом высокую точность благодаря distillation.
Узкие места в продакшене
Distillation — не серебряная пуля. Вот подводные камни, которые нужно учитывать:
-
Качество учителя влияет на ученика. Если учитель ошибается в систематической манере, ученик усвоит эти ошибки. Это особенно критично в задачах безопасности, где систематические ошибки могут быть опасны.
-
Температурное масштабирование требует тонкой настройки. Слишком низкая температура — и ученик выучит только “уверенность” учителя, игнорируя более тонкие различия. Слишком высокая — и обучение станет нестабильным.
-
Размер модели-учителя. Distillation эффективен, когда учитель значительно больше ученика (10-100 раз). Если разница в размерах невелика, выгода может быть неочевидной.
-
Время обучения. Distillation требует больше эпох по сравнению с обычным обучением ученика, так как ученику нужно не просто выучить ответы, а понять логику учителя.
-
Архитектурные ограничения. Не все архитектуры хорошо поддаются distillation. Например, трансформеры с их attention механизмами требуют особого подхода к передаче знаний.
Когда использовать distillation, а когда — нет
Distillation — мощный инструмент, но не универсальный. Используйте его, когда:
- У вас есть ресурсоемкая модель-учитель, которую нужно развернуть на ограниченных устройствах
- Требуется сохранить большую часть производительности оригинальной модели
- У вас есть вычислительные ресурсы для процесса distillation
- Время вывода модели критично, а точность должна быть близка к оригиналу
Избегайте distillation, когда:
- Модель-учитель уже достаточно компактна
- Требуется максимальная точность, а размер не критичен
- У вас нет возможности провести двухэтапное обучение (сначала учитель, потом ученик)
- Задача требует интерпретируемости, и простота модели важнее точности
Distillation — это не просто техника сжатия, а способ передачи абстрактных знаний от одной нейронной сети к другой. В мире, где каждая миллисекунда и мегабайт на счете, это становится все более ценным инструментом в арсенале ML-инженера. Но как и любой инструмент, он требует понимания своих ограничений и правильного применения.
Читайте также