Трендовые github проекты в нашем телеграм канале. Подпишись 👉
Трендовые github проекты в нашем телеграм канале. Подпишись 👉 gRPC в Python: Protobuf, aio, streaming
gRPC стал стандартом де-факто для внутренней коммуникации в микросервисных архитектурах, предлагая высокую производительность, строгую типизацию и поддержку потоковой передачи данных. Однако его внедрение в Python-проекты часто сталкивается с непониманием нюансов работы Protocol Buffers, асинхронной реализации и потоковых вызовов. Эта статья погрузит вас в механику gRPC для Python, разберет практические аспекты его использования и укажет на подводные камни, с которыми сталкиваются даже опытные разработчики.
Технический вызов - высокопроизводительная коммуникация в микросервисах
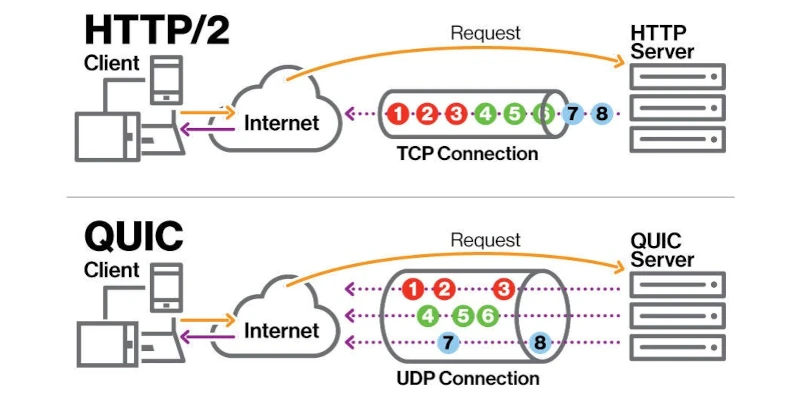
Современные распределенные системы сталкиваются с фундаментальным вызовом: как обеспечить эффективную коммуникацию между сервисами без потери производительности и с минимальными накладными расходами. REST API поверх HTTP/1.1, несмотря на свою популярность, имеет ограничения в виде избыточной информации в заголовках и блокирующего характера запросов. gRPC, разработанный Google, решает эти проблемы, используя HTTP/2 в качестве транспортного протокола и Protocol Buffers для сериализации данных.
HTTP/2 обеспечивает multiplexing (возможность отправки нескольких запросов по одному соединению), сжатие заголовков и приоритизацию потоков, что значительно снижает задержки и повышает throughput. Protocol Buffers, в свою очередь, обеспечивают компактное двоичное кодирование данных, что уменьшает объем передаваемых данных и ускоряет сериализацию/десериализацию по сравнению с JSON/XML.
Комбинация этих технологий делает gRPC идеальным выбором для внутренних коммуникаций в микросервисной архитектуре, особенно в тех случаях, когда важна производительность и строгая типизация данных.
gRPC в деталях
Протокол HTTP/2
gRPC построен поверх HTTP/2, что дает ему ряд ключевых преимуществ перед традиционным REST API:
-
Multiplexing: Возможность отправки нескольких запросов и получения ответов по одному TCP-соединению. Это устраняет проблему “head-of-line blocking”, когда медленный запрос блокирует последующие.
-
Binary framing: Данные передаются в бинарном формате, что делает передачу более эффективной по сравнению с текстовым форматом.
-
Server push: Сервер может отправлять данные клиенту без явного запроса, что полезно для сценариев подписки.
-
Compression: Заголовки HTTP сжимаются с помощью HPACK, что снижает накладные расходы.
Однако важно понимать, что HTTP/2 требует HTTPS в производственных средах (хотя для разработки можно использовать HTTP), что добавляет слой шифрования и может незначительно влиять на производительность.
Protocol Buffers как основа
Protocol Buffers (protobuf) — это механизм сериализации структурированных данных, разработанный Google. Он позволяет определять структуру ваших данных в файле .proto, а затем генерировать код для различных языков программирования для чтения и записи этих данных.
Ключевые преимущества protobuf:
-
Производительность: Бинарный формат сериализации значительно компактнее текстовых форматов вроде JSON и быстрее обрабатывается.
-
Схема данных: Явное определение структуры данных обеспечивает строгую типизацию и возможность проверки на уровне схемы.
-
Версионирование: Протobuf поддерживает обратную и прямую совместимость, позволяя добавлять поля без нарушения работы существующих клиентов.
Однако есть и компромиссы:
- Сложность отладки (бинарный формат нечитаем)
- Необходимость компиляции .proto файлов в код для целевого языка
- Ограниченная поддержка динамических языков (в Python требуется генерация кода)
Пример .proto файла:
syntax = "proto3";
package example;
service UserService {
rpc GetUser(GetUserRequest) returns (User) {}
rpc ListUsers(ListUsersRequest) returns (stream User) {}
rpc CreateUser(stream UserRequest) returns (UserResponse) {}
rpc Chat(stream Message) returns (stream Message) {}
}
message User {
int32 id = 1;
string name = 2;
string email = 3;
}
message GetUserRequest {
int32 id = 1;
}
message ListUsersRequest {
int32 limit = 1;
}
message UserRequest {
User user = 1;
}
message UserResponse {
bool success = 1;
string message = 2;
}
message Message {
string text = 1;
string from = 2;
}Практическая реализация
Установка и настройка
Для начала работы с gRPC в Python необходимо установить несколько пакетов:
pip install grpcio grpcio-toolsДля работы с асинхронным gRPC (aio) также потребуется:
pip install grpcio aioДля генерации кода из .proto файлов:
pip install grpcio-toolsГенерация кода из .proto файла выполняется с помощью:
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. your_service.protoЭтот создаст два файла:
your_service_pb2.py- содержит классы для данныхyour_service_pb2_grpc.py- содержит клиентские и серверные заглушки
Определение сервисов и сообщений
Как уже показано в примере выше, .proto файл определяет:
- Сервисы (сервисы и их RPC методы)
- Сообщения (структуры данных)
Каждое поле имеет номер, который используется при сериализации. Эти числа не должны меняться при изменении схемы, чтобы обеспечить совместимость.
Синхронная реализация
Вот как выглядит простой сервер gRPC в Python:
from concurrent import futures
import grpc
import your_service_pb2
import your_service_pb2_grpc
class UserServiceServicer(your_service_pb2_grpc.UserServiceServicer):
def GetUser(self, request, context):
# Логика получения пользователя
user = your_service_pb2.User(
id=request.id,
name="John Doe",
email="john@example.com"
)
return user
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
your_service_pb2_grpc.add_UserServiceServicer_to_server(UserServiceServicer(), server)
server.add_insecure_port('[::]:50051')
server.start()
server.wait_for_termination()
if __name__ == '__main__':
serve()Клиент:
import grpc
import your_service_pb2
import your_service_pb2_grpc
def run():
with grpc.insecure_channel('localhost:50051') as channel:
stub = your_service_pb2_grpc.UserServiceStub(channel)
response = stub.GetUser(your_service_pb2.GetUserRequest(id=1))
print(f"User: {response.name}, {response.email}")
if __name__ == '__main__':
run()Асинхронная реализация с aio
Асинхронная реализация в gRPC для Python использует библиотеку aio. Вот как выглядит сервер:
import asyncio
import grpc
import your_service_pb2
import your_service_pb2_grpc
class AsyncUserServiceServicer(your_service_pb2_grpc.UserServiceServicer):
async def GetUser(self, request, context):
# Асинхронная логика получения пользователя
await asyncio.sleep(0.1) # Имитация асинхронной операции
user = your_service_pb2.User(
id=request.id,
name="Jane Doe",
email="jane@example.com"
)
return user
async def serve():
server = aio.server()
your_service_pb2_grpc.add_UserServiceServicer_to_server(AsyncUserServiceServicer(), server)
listen_addr = '[::]:50051'
server.add_insecure_port(listen_addr)
await server.start()
await server.wait_for_termination()
if __name__ == '__main__':
asyncio.run(serve())Асинхронный клиент:
import aio
import grpc
import your_service_pb2
import your_service_pb2_grpc
async def run():
async with grpc.aio.insecure_channel('localhost:50051') as channel:
stub = your_service_pb2_grpc.UserServiceStub(channel)
response = await stub.GetUser(your_service_pb2.GetUserRequest(id=1))
print(f"User: {response.name}, {response.email}")
if __name__ == '__main__':
aio.run(run())Streaming
gRPC поддерживает четыре типа вызовов:
Unary вызовы
Самый простой тип вызова, где клиент отправляет один запрос и получает один ответ. Мы уже рассмотрели пример выше.
Server Streaming
В этом случае клиент отправляет один запрос, а сервер возвращает поток данных. Пример:
Сервер:
class UserServiceServicer(your_service_pb2_grpc.UserServiceServicer):
def ListUsers(self, request, context):
# Генерация потока пользователей
for i in range(request.limit):
yield your_service_pb2.User(
id=i,
name=f"User {i}",
email=f"user{i}@example.com"
)Клиент:
def run():
with grpc.insecure_channel('localhost:50051') as channel:
stub = your_service_pb2_grpc.UserServiceStub(channel)
responses = stub.ListUsers(your_service_pb2.ListUsersRequest(limit=5))
for response in responses:
print(f"User: {response.name}, {response.email}")Client Streaming
Клиент отправляет поток данных, а сервер возвращает один ответ.
Сервер:
class UserServiceServicer(your_service_pb2_grpc.UserServiceServicer):
def CreateUser(self, request_iterator, context):
users = []
for user_request in request_iterator:
users.append(user_request.user)
# Логика создания пользователя
return your_service_pb2.UserResponse(
success=True,
message=f"Created {len(users)} users"
)Клиент:
def run():
with grpc.insecure_channel('localhost:50051') as channel:
stub = your_service_pb2_grpc.UserServiceStub(channel)
user_requests = [
your_service_pb2.UserRequest(user=your_service_pb2.User(id=1, name="Alice", email="alice@example.com")),
your_service_pb2.UserRequest(user=your_service_pb2.User(id=2, name="Bob", email="bob@example.com"))
]
responses = stub.CreateUser(iter(user_requests))
for response in responses:
print(f"Response: {response.message}")Bidirectional Streaming
Наиболее сложный случай, когда и клиент, и сервер обмениваются потоками данных. Это реализуется как два независимых потока, которые работают одновременно.
Сервер:
class ChatServiceServicer(your_service_pb2_grpc.ChatServiceServicer):
async def Chat(self, request_iterator, context):
async for message in request_iterator:
# Обработка входящего сообщения
response = your_service_pb2.Message(
text=f"Echo: {message.text}",
from=message.to if hasattr(message, 'to') else "Server"
)
yield responseКлиент:
async def run():
async with grpc.aio.insecure_channel('localhost:50051') as channel:
stub = your_service_pb2_grpc.ChatStub(channel)
# Поток для чтения сообщений от сервера
async def read_responses():
async for response in stub.Chat(messages):
print(f"Received: {response.text}")
# Поток для отправки сообщений серверу
messages = [
your_service_pb2.Message(text="Hello", from="Client"),
your_service_pb2.Message(text="How are you?", from="Client")
]
# Запускаем чтение и запись одновременно
await asyncio.gather(
read_responses(),
stub.Chat(iter(messages))
)Узкие места и trade-offs
Несмотря на все преимущества, gRPC имеет ряд ограничений и проблем, о которых стоит знать:
-
Отладка: Бинарный формат Protocol Buffers затрудняет отладку. Инструменты вроде
grpcurlиprotoc-gen-docпомогают, но процесс все равно сложнее, чем с REST API. -
Внешние API: gRPC плохо подходит для публичных API, так как требует клиентов с поддержкой Protocol Buffers. Для публичных API лучше использовать REST с JSON, так как проще для разработчиков браузерных клиентов.
-
Производительность в малых нагрузках: Для небольших сообщений накладные расходы на сериализацию могут превышать преимущества от использования binary формата.
-
Поддержка браузеров: gRPC не поддерживается напрямую в браузерах, хотя есть экспериментальная поддержка через gRPC-Web.
-
Сложность: Внедрение gRPC требует понимания новых концепций, генерации кода и дополнительной инфраструктуры (например, сервис обнаружения сервисов).
-
SSL/TLS: Хотя gRPC может работать без шифрования (для разработки), в продакшене требуется HTTPS, что добавляет накладные расходы.
-
Обработка ошибок: gRPC использует коды статуса (Status Codes) вместо HTTP статусов, что требует привыкания.
Заключение - когда использовать gRPC
gRPC — мощный инструмент для внутренней коммуникации в микросервисах, особенно когда:
- Высокая производительность критична
- Требуется строгая типизация данных
- Работаете с потоковыми данными
- Система состоит преимущественно из сервисов на Python или других языках с поддержкой gRPC
Однако для публичных API, простых CRUD-сервисов или когда важна простота разработки и отладки, REST API с JSON может быть более подходящим выбором.
В конечном счете, решение об использовании gRPC должно основываться на требованиях вашего проекта, а не на модных технологиях. Для многих современных систем gRPC становится естественным выбором для внутренней коммуникации, обеспечивая производительность и надежность.
Читайте также