 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Как масштабировать security scanning: Kafka, Postgres и API без лишнего железа
Security scanning часто выглядит как простая задача: взять цель, проверить, сохранить результат, показать пользователю. Но когда таких проверок становится тысячи в минуту, система превращается в распределённый pipeline. Узкими местами становятся Kafka consumers, Postgres queries, API limits, очередь задач и хранение результатов.
Масштабирование не всегда требует нового железа. Часто первый 10x прирост даёт оптимизация архитектуры: правильная очередь, batch processing, индексы, backpressure и наблюдаемость.
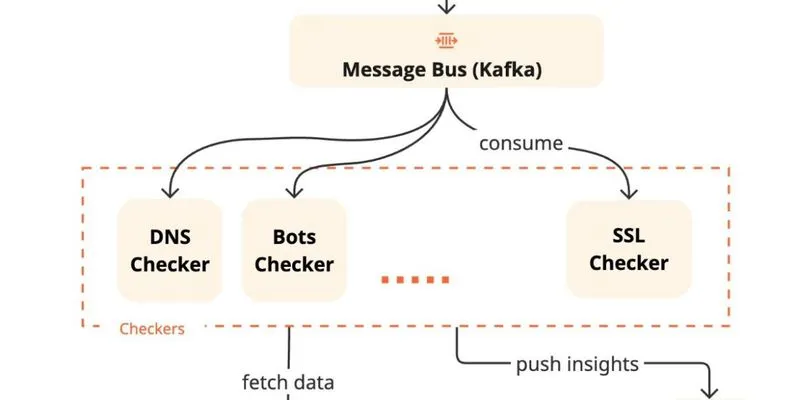
Pipeline сканирования
Типовая схема:
API → queue → workers/scanners → result processor → database → dashboard/alertsКаждый слой должен быть независимым. API принимает запрос и ставит задачу. Workers обрабатывают задачи параллельно. Result processor нормализует результаты. База хранит состояние и историю.
Если API синхронно ждёт завершения скана, система быстро упрётся в timeouts и плохой UX.
Kafka consumers
Kafka хорошо подходит для потоковой обработки задач и результатов, но производительность зависит от consumers:
- количество partitions;
- consumer group;
- batch size;
- commit strategy;
- retry policy;
- обработка poison messages;
- баланс между throughput и latency.
Если consumer обрабатывает сообщения по одному и часто пишет offset, пропускная способность будет низкой. Batch processing и аккуратные commits могут дать большой выигрыш.
Backpressure
Сканеры могут быть быстрее базы или внешних API. Если не контролировать поток, очередь заполнится, latency вырастет, а система начнёт падать каскадом.
Backpressure нужен на нескольких уровнях:
- rate limits на входе;
- лимит активных задач;
- динамический throttling workers;
- priority queues;
- circuit breakers для внешних зависимостей;
- отдельные очереди для тяжёлых задач.
Лучше честно замедлить приём задач, чем потерять контроль над pipeline.
Postgres как узкое место
Security scanning создаёт много записей: scan metadata, findings, statuses, history, assets, timestamps. Postgres может выдерживать большой поток, если схема и запросы спроектированы правильно.
Что проверять:
- индексы под реальные queries;
- отсутствие N+1;
- batch inserts;
- partitioning больших таблиц;
- autovacuum;
- connection pooling;
- размер JSONB-полей;
- explain analyze для горячих запросов.
Иногда один плохой dashboard query съедает больше ресурсов, чем сами workers.
Idempotency
В распределённом pipeline задачи могут повторяться: retry, rebalance, network error, worker crash. Поэтому обработка результатов должна быть идемпотентной.
Практики:
- stable scan id;
- unique keys для findings;
- upsert вместо слепой вставки;
- статусы с переходами;
- дедупликация сообщений;
- audit trail повторов.
Без idempotency retries превращаются в дубли и неверные отчёты.
Observability
Для масштабирования нужны метрики:
- queue lag;
- scans per second;
- worker utilization;
- processing latency;
- DB query latency;
- error rate;
- retry count;
- failed scans;
- API p95/p99;
- storage growth.
Метрики должны показывать не только «система работает», но и где именно появляется задержка.
Оптимизация без железа
Перед добавлением серверов стоит проверить:
- можно ли увеличить batch size;
- есть ли лишние запросы;
- правильно ли работают индексы;
- не слишком ли частые updates статуса;
- можно ли кэшировать справочники;
- не блокируют ли workers друг друга;
- есть ли тяжёлые синхронные операции в API.
Часто bottleneck — не CPU, а неудачная последовательность операций.
Итог
Security scanning масштабируется как любой data pipeline: очередь, consumers, workers, база, backpressure и observability. Рост производительности начинается с измерений, а не с покупки железа.
Если система видит queue lag, latency, ошибки и горячие запросы, её можно оптимизировать точечно. Если нет — масштабирование превращается в угадывание.
Читайте также
