 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → AI как новая поверхность атаки: какие инциденты стоит учитывать в архитектуре
AI-инструменты становятся опасными не потому, что модель «злая», а потому что им дают доступ к рабочему контексту: файлам, почте, репозиториям, браузеру, базам, CRM, внутренним документам и API. Чем больше прав получает ассистент, тем больше его поверхность атаки.
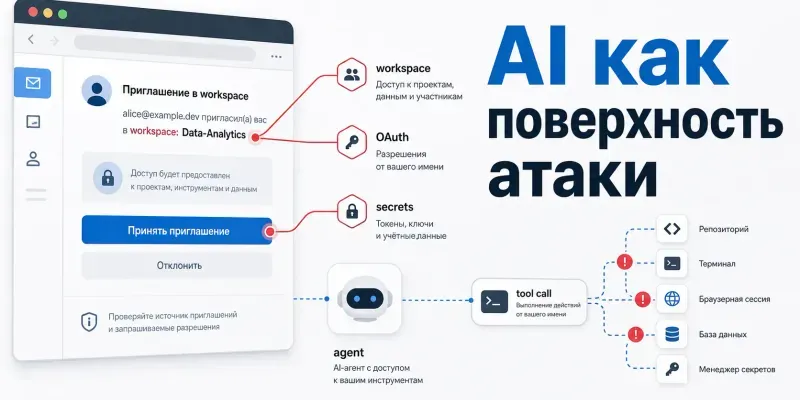
Новая threat model должна учитывать не только уязвимости модели, но и весь контур вокруг неё: токены, workspace invites, плагины, agents, external content и data pipelines.
Недоверенный контент как инструкция
AI-агент читает текст и может воспринимать его как задачу. Если в issue, email, web page или документ встроена вредная инструкция, агент может попытаться её выполнить. Это делает prompt injection практической угрозой.
Защита строится на разделении:
- данные — это данные;
- инструкции — только из доверенного источника;
- опасные действия требуют approval;
- tool calls логируются;
- внешние документы не получают права управлять агентом.
Токены и workspace-доступы
Многие AI-сервисы интегрируются через OAuth, browser sessions и workspace invites. Фишинг может выглядеть как легитимное приглашение в AI-workspace. Пользователь подтверждает доступ, и злоумышленник получает данные или permissions.
Нужны базовые меры:
- review OAuth-приложений;
- ограничение scopes;
- регулярная ротация токенов;
- запрет личных интеграций для рабочих данных;
- мониторинг новых connected apps.
Утечки баз и артефактов
AI-проекты часто создаются быстро: notebooks, embeddings, векторные базы, logs, datasets, temporary buckets. Если доступы настроены слабо, наружу могут попасть промпты, пользовательские данные, токены или training artifacts.
Любая AI-инфраструктура должна проходить те же проверки, что и обычный production: secrets, network exposure, auth, backups, retention, audit.
Агентные сбои
AI-агент может удалить файл, изменить код, выполнить неправильную команду или принять неверное решение. Это не всегда атака, но последствия похожи на инцидент.
Поэтому нужны:
- sandbox;
- least privilege;
- dry-run;
- diff preview;
- approval для destructive actions;
- rollback;
- лимиты на tool calls.
Итог
AI становится новой поверхностью атаки там, где получает доступ к данным и действиям. Безопасность должна проектироваться не вокруг «умности модели», а вокруг прав, интеграций, недоверенного контента и наблюдаемости.
Главный вопрос: что сможет сделать злоумышленник, если заставит агента поверить вредной инструкции или украдёт его токен? Ответ на него и должен определять архитектуру защиты.
Читайте также
