 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Когда атакующим становится не скрипт, а модель
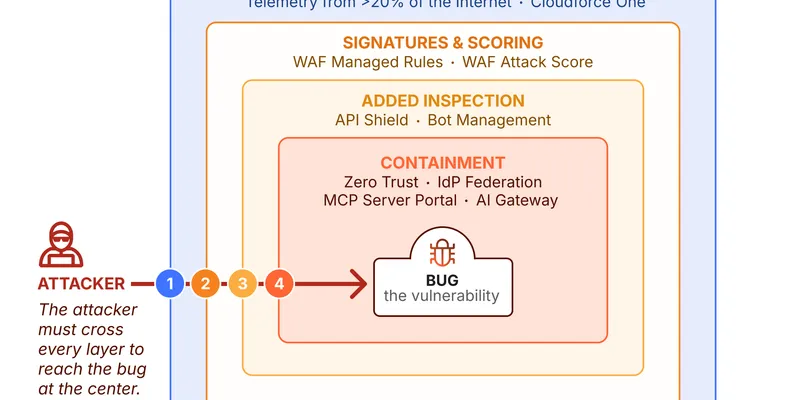
Классическая защита веб-сервисов долго строилась вокруг понятной гонки: нашли уязвимость, оценили риск, выпустили патч, раскатили обновление. Эта модель всё ещё важна, но для современных систем её уже недостаточно. Если атакующий использует продвинутую AI-модель для поиска путей эксплуатации, скорость реакции остаётся только одним из факторов. Не менее важным становится устройство самой архитектуры вокруг уязвимого места.
Frontier-модели меняют экономику атаки. Они могут быстро перебирать варианты, читать документацию, связывать разрозненные симптомы, генерировать payload и адаптировать стратегию под ответы системы. Даже если модель не обладает магическим доступом к инфраструктуре, она снижает стоимость рутинной исследовательской работы. То, что раньше требовало часов ручного анализа, может превратиться в поток гипотез, проверок и уточнений.
Поэтому вопрос «как быстро мы закрываем CVE» нужно дополнять другим: что произойдёт, если уязвимость всё-таки будет использована до патча? Хорошая архитектура должна не только предотвращать ошибку, но и ограничивать её последствия.
Почему патч не является единственной линией обороны
Патч — это точечное исправление известной проблемы. Он отлично работает, когда у команды есть ясное описание бага, воспроизводимый сценарий, готовое обновление и окно для безопасной раскатки. Но в реальной инфраструктуре между обнаружением и полной установкой исправления всегда есть задержка.
Эта задержка складывается из нескольких частей:
- уязвимость нужно подтвердить и понять, какие сервисы затронуты;
- владельцы систем должны оценить совместимость обновления;
- обновление нужно протестировать, особенно если сервис критичен;
- rollout может быть поэтапным, чтобы не обрушить production;
- часть legacy-компонентов может не поддерживать быстрый апгрейд.
Для массового сканера такая задержка уже опасна. Для атакующего, усиленного AI, она становится ещё более ценной: модель может быстрее найти обходной путь, подобрать специфичный запрос или связать баг с особенностями конкретной конфигурации.
Отсюда главный вывод: защита должна предполагать, что патч иногда опаздывает. Не потому что команда плохо работает, а потому что сложная распределённая система не обновляется мгновенно.
Архитектура вокруг уязвимости
Практичный подход начинается с вопроса о контексте. Одна и та же ошибка может быть почти безвредной в изолированном сервисе и критичной в компоненте, который имеет доступ к внутренним API, секретам или административным операциям.
Имеет значение не только наличие бага, но и то, что окружает уязвимый компонент:
- какие права есть у процесса;
- какие сети доступны из его runtime;
- можно ли через него обратиться к внутренним сервисам;
- какие токены и переменные окружения присутствуют;
- есть ли строгая проверка входящих и исходящих запросов;
- насколько хорошо логируются подозрительные действия.
Если сервис с уязвимостью работает с минимальными правами, не видит приватные сети и не содержит долговечных секретов, успешная эксплуатация превращается в локальный инцидент. Если же он находится в плоской сети и имеет широкие credentials, баг становится входной дверью во всю инфраструктуру.
Модель «customer zero» для собственной защиты
Полезная практика — относиться к своей инфраструктуре как к первому клиенту собственной защитной архитектуры. Это означает не просто продавать или внедрять security-механизмы для других, а регулярно применять их к себе: проверять реальные сервисы, реальные цепочки доступа и реальные сценарии эксплуатации.
Такой подход хорош тем, что быстро вскрывает разрыв между красивой схемой и production-действительностью. На диаграмме может быть zero trust, сегментация и централизованный контроль. В живой системе обнаруживаются исключения: временные allowlist, старые токены, обходные maintenance-эндпоинты, сервисы без нормального ownership и компоненты, которые никто давно не пересобирал.
Для защиты от AI-усиленных атак это особенно важно. Модель не обязана понимать внутреннюю политику компании, но она может последовательно искать несостыковки. Если в архитектуре есть маленькие технические долги, объединённые в цепочку, автоматизированный исследователь найдёт их быстрее, чем человек, который смотрит только на один сервис.
Минимизация blast radius
Главный принцип — уязвимость не должна автоматически превращаться в компрометацию соседних систем. Для этого нужны привычные, но часто недооценённые меры.
Во-первых, строгая сегментация сети. Сервис, принимающий публичный трафик, не должен без необходимости обращаться к административным интерфейсам, базам данных и внутренним control plane. Даже внутри Kubernetes или private cloud стоит явно описывать, какие направления разрешены.
Во-вторых, минимальные права. Service account должен иметь только те permissions, которые нужны для текущей функции. Если компонент читает публичные данные, ему не нужен доступ на запись в критичные хранилища. Если задача временная, credentials тоже должны быть временными.
В-третьих, изоляция секретов. Переменные окружения удобны, но часто превращаются в свалку токенов. Лучше использовать секреты с коротким сроком жизни, привязкой к workload identity и понятным аудитом обращения.
В-четвёртых, безопасные значения по умолчанию. Новые сервисы не должны автоматически попадать в доверенную зону. Доступ к внутренним API, egress в интернет и привилегированные роли должны выдаваться явно.
Наблюдаемость как часть защиты
Если атаки становятся более адаптивными, логи и метрики нужны не только для postmortem. Они должны помогать быстро понять, что система ведёт себя необычно.
Полезно отслеживать:
- резкий рост ошибок валидации и нестандартных HTTP-кодов;
- последовательности запросов, похожие на исследование поверхности атаки;
- обращения к редким endpoint;
- необычный egress из сервиса;
- попытки доступа к внутренним адресам;
- изменение профиля latency после специфичных payload.
Важно, чтобы эти сигналы были связаны с контекстом workload: версией приложения, deployment, service account, namespace, origin трафика. Иначе команда получает набор разрозненных событий, по которым сложно собрать цепочку.
Для homelab это тоже применимо. Даже если инфраструктура небольшая, стоит иметь централизованные access logs, понятные firewall rules и алерты на неожиданный исходящий трафик. AI-усиленная атака против домашнего сервера не становится менее неприятной только потому, что это не enterprise.
Что можно внедрить в небольшом контуре
Не каждой команде нужен сложный security platform. Но базовый набор мер доступен почти всем.
Для публичных веб-сервисов стоит включить reverse proxy с rate limiting, ограничением методов, нормализацией заголовков и понятными логами. Для контейнеров — read-only filesystem там, где возможно, drop capabilities, отдельные users и запрет privileged-режима. Для внутренних сервисов — сетевые политики или хотя бы firewall-правила, которые запрещают лишний east-west трафик.
Отдельно стоит проверить зависимости между компонентами. Если один небольшой сервис имеет доступ к базе, объектному хранилищу, очереди сообщений и CI-токенам одновременно, это красный флаг. Удобство эксплуатации не должно превращать любой баг в универсальный pivot.
Ещё один практичный шаг — регулярные tabletop-упражнения. Берётся конкретный сервис и задаётся вопрос: «что будет, если атакующий получит выполнение кода именно здесь?» Ответ должен включать не только патч, но и пределы ущерба, доступные логи, способ отзыва секретов и план изоляции.
Как меняется роль разработчика и DevOps
Защита от frontier-моделей не означает, что каждый разработчик должен стать специалистом по offensive security. Но она повышает требования к инженерной гигиене. Код, деплой, секреты, сетевые правила и observability больше нельзя рассматривать отдельно.
Разработчик проектирует не только функцию, но и границы её поведения при сбое. DevOps отвечает не только за uptime, но и за то, чтобы компрометация одного workload не открывала всю платформу. Security-команда должна давать не абстрактные запреты, а понятные guardrails: шаблоны сервисов, политики доступа, проверки в CI и быстрый способ увидеть рискованную конфигурацию.
В итоге скорость патчей остаётся важной, но перестаёт быть единственной метрикой зрелости. Более сильный показатель — способность инфраструктуры пережить неизвестную или ещё не исправленную уязвимость без каскадного провала. Именно эта архитектурная устойчивость становится ключевой защитой в мире, где автоматизированный атакующий становится всё умнее и дешевле.
Читайте также
