 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Локальная LLM как слой диагностики для Oracle
Классический мониторинг баз данных хорошо показывает, что происходит: выросло время ожиданий, увеличилась нагрузка, просели отдельные классы операций, изменились графики в Grafana. Но он не всегда помогает быстро понять, почему это произошло и с чего начать диагностику.
Идея AI-мониторинга в закрытом контуре как раз закрывает этот разрыв. Метрики продолжают собираться привычным способом, но рядом появляется локальная языковая модель, которая получает агрегированные показатели и формирует текстовое объяснение: что изменилось, какие причины вероятны и какие проверки стоит сделать в первую очередь.
Эксперимент с Oracle, Python, Ollama и представлением V$WAITCLASSMETRIC хорошо показывает не хайповое, а практичное применение LLM в инфраструктуре: модель не управляет базой и не заменяет DBA, а работает как дополнительный слой интерпретации поверх мониторинга.
Проблема: графики есть, объяснения нет
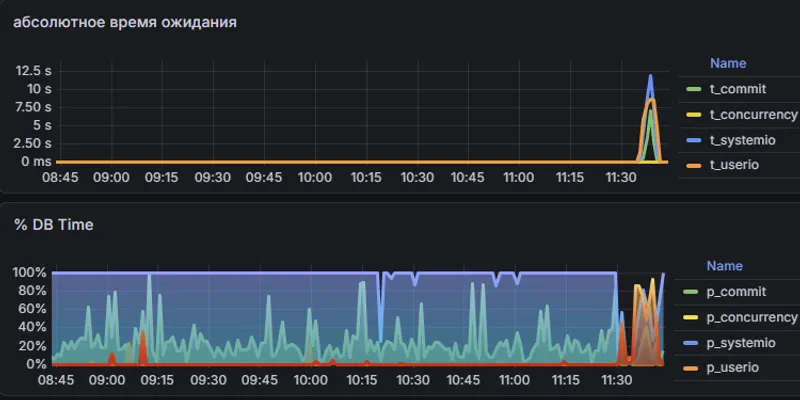
В инфраструктуре часто уже есть сбор метрик и визуализация. Например, для Oracle можно регулярно читать данные из V$WAITCLASSMETRIC и строить графики по классам ожиданий:
User I/O;Commit;Concurrency;System I/O;Network;- другим wait class.
Grafana отлично показывает динамику. Если время ожидания резко выросло, инженер это увидит. Но дальше начинается ручная работа: нужно вспомнить контекст, сопоставить несколько графиков, проверить активные сессии, посмотреть планы запросов, оценить storage, блокировки, commits и конкуренцию.
Для опытного DBA это нормальная процедура. Для дежурного инженера или небольшой команды без выделенного администратора баз данных — уже проблема. Особенно если инцидент происходит ночью или в проекте нет глубокого Oracle-эксперта.
Где здесь помогает локальная LLM
LLM можно использовать не для принятия решений, а для объяснения наблюдаемых симптомов. На вход модель получает структурированное описание метрик: какие wait class изменились, насколько сильно, за какой период, что выглядит аномально по сравнению с предыдущими значениями.
На выходе она может сформировать:
- краткое резюме текущего состояния;
- список наиболее вероятных причин;
- гипотезы для проверки;
- рекомендации по следующему шагу диагностики;
- объяснение простым языком для on-call инженера.
Ключевой момент — модель должна работать с уже подготовленным контекстом, а не с сырым потоком данных. Python-скрипт или отдельный backend-сервис может собрать метрики, нормализовать их и передать в Ollama аккуратный prompt.
Условно процесс выглядит так:
Oracle -> Python collector -> метрики wait class -> prompt -> Ollama -> текстовое объяснение -> Grafana/дашбордТакой подход не ломает существующий monitoring stack. Он добавляет рядом слой аналитического комментария.
Почему закрытый контур важен
Для мониторинга баз данных вопрос приватности критичен. Метрики сами по себе могут раскрывать внутреннюю архитектуру, названия сервисов, характер нагрузки, временные пики, иногда даже бизнес-контекст. Отправлять всё это во внешний API можно не всегда.
Поэтому использование Ollama или другой локально развёрнутой модели выглядит логично. Инфраструктурные данные остаются внутри периметра, а команда получает AI-помощника без передачи чувствительной информации наружу.
Плюсы закрытого контура:
- данные не уходят к внешнему LLM-провайдеру;
- можно работать в изолированной сети;
- проще соответствовать внутренним security policy;
- ниже риск случайной утечки инфраструктурного контекста;
- модель можно запускать рядом с monitoring stack.
Минусы тоже есть: локальная модель требует ресурсов, её качество может быть ниже топовых облачных моделей, а prompts и формат входных данных нужно тщательно проектировать.
Роль Python в такой схеме
Python здесь удобен как связующий слой. Он может одновременно работать с Oracle, HTTP API Ollama и системой визуализации.
Типовые задачи Python-сервиса:
- Подключиться к Oracle.
- Прочитать нужные метрики из
V$WAITCLASSMETRIC. - Сравнить значения с предыдущими измерениями.
- Найти заметные отклонения.
- Сформировать компактный prompt для LLM.
- Получить текстовый ответ.
- Сохранить объяснение или отдать его в Grafana/внутренний dashboard.
Важно не превращать prompt в свалку. Чем лучше подготовлены данные, тем полезнее ответ модели. Вместо сотни строк сырых метрик лучше передать агрегированную картину: какие классы ожиданий выросли, насколько, за какой интервал и какие значения были до этого.
Как не переоценить AI-слой
AI-комментарий к мониторингу — это не автомагический root cause analysis. Модель не видит всю систему, если вы не передали ей контекст. Она может ошибиться, дать слишком общий совет или выбрать не самую вероятную гипотезу.
Поэтому правильная роль LLM в мониторинге — помощник для triage, а не автономный администратор базы данных.
Хороший ответ модели должен восприниматься как:
- подсказка для инженера;
- список направлений проверки;
- объяснение графика человеческим языком;
- черновик incident note;
- способ быстрее войти в контекст.
Плохая практика — автоматически выполнять рекомендации модели в production. Особенно если речь идёт о базе данных: изменять параметры, убивать сессии, перестраивать индексы или менять конфигурацию без проверки нельзя.
Практический сценарий для команды
Представим небольшой production-контур: Oracle, Grafana, Python collector и локальная LLM через Ollama. Каждую минуту collector читает wait class metrics и сохраняет их для графиков. Если видит аномалию, он дополнительно вызывает модель.
На дашборде рядом с графиком появляется текст:
За последние 5 минут вырос User I/O. Возможные причины: увеличение чтения с диска, тяжелый запрос без подходящего индекса, холодный cache или деградация storage. Проверьте top SQL по physical reads, активные сессии и latency дисковой подсистемы.Даже если это не финальный диагноз, такой комментарий экономит время. Дежурному не нужно начинать с пустого листа. Он получает первые гипотезы и список проверок.
Что стоит продумать перед внедрением
Перед тем как добавлять LLM в мониторинг, стоит ответить на несколько вопросов.
Какие данные можно передавать модели
Даже локальной модели лучше не отдавать лишнее. Не нужны персональные данные, содержимое запросов с чувствительной информацией, секреты и полные connection strings. Для диагностики часто достаточно агрегированных чисел, названий wait class и технического контекста.
Как оценивать качество ответов
Нужно собрать набор типовых ситуаций и проверить, что модель даёт полезные рекомендации. Например: рост I/O, блокировки, частые commits, network wait, конкуренция за ресурсы. Без такой проверки AI-слой может выглядеть красиво, но не помогать в реальных инцидентах.
Где хранить объяснения
Ответы LLM полезно сохранять рядом с метриками. Тогда можно вернуться к инциденту, сравнить прогноз модели с реальной причиной и улучшить prompts.
Как ограничить уверенность модели
В prompt стоит явно требовать формулировки в стиле «возможные причины» и «что проверить», а не «точная причина». Это снижает риск ложной уверенности.
Чем это полезно для homelab и production
В homelab такой подход интересен как учебный проект: можно связать базу данных, Grafana, Python и локальную модель в одну систему и понять, как строятся AI-assisted operations.
В production ценность другая: ускорение первичной диагностики и снижение нагрузки на экспертов. Особенно в командах, где один инженер отвечает сразу за приложение, базу, инфраструктуру и мониторинг.
AI-мониторинг не заменяет нормальные alerts, SLO, runbooks и знания DBA. Но он может стать удобным интерактивным слоем поверх уже существующей observability-системы.
Итог
Эксперимент с Oracle, Python, Ollama и V$WAITCLASSMETRIC показывает хороший сценарий применения LLM в инфраструктуре: не генерировать абстрактные советы, а объяснять конкретные технические метрики в закрытом контуре.
Самая сильная сторона такого подхода — безопасность и практичность. Данные остаются внутри, monitoring stack почти не меняется, а инженеры получают более понятный контекст при разборе проблем.
Если внедрять это аккуратно — с ограничением данных, проверкой качества ответов и явной ролью «помощника для диагностики», — локальная LLM может стать полезным дополнением к Grafana и классическому мониторингу баз данных.
Читайте также
