 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Нейросеть там, где нет ни Python, ни памяти под модель
Мини-проект с запуском перцептрона на обычном непрограммируемом инженерном калькуляторе выглядит как забавный трюк, но в нём есть полезная инженерная идея. Он заставляет разложить нейросеть до самых простых операций: умножений, сложений, функции активации и набора коэффициентов. Когда исчезают NumPy, фреймворки, GPU и даже возможность написать программу прямо на устройстве, становится хорошо видно, что именно делает маленькая модель во время инференса.
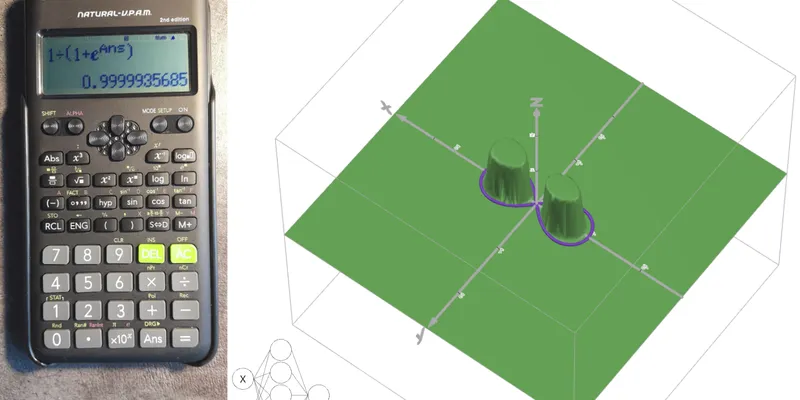
В качестве модели используется компактная сеть 2-5-1: два входа, один скрытый слой из пяти нейронов и один выход. Обучение выполняется на Python без сторонних библиотек вроде NumPy, а затем рассчитанные веса и смещения переносятся в ручной сценарий вычислений на Casio Fx-82-ES Plus 2nd edition. Задача тоже выбрана геометрическая: определить, попадает ли точка в область графика лемнискаты Бернулли.
Почему формат 2-5-1 удобен для ручного инференса
Сеть 2-5-1 достаточно мала, чтобы её можно было проверить вручную, но уже не сводится к одной линейной границе. На вход подаются координаты точки x и y. Каждый из пяти нейронов скрытого слоя получает оба значения, умножает их на свои веса, добавляет смещение и пропускает результат через функцию активации. Выходной нейрон агрегирует пять промежуточных значений и выдаёт оценку принадлежности точки нужной области.
Для практического переноса на калькулятор это важный компромисс. Если скрытых нейронов будет слишком мало, модель может не уловить форму области. Если слишком много — ручной инференс быстро превратится в таблицу из десятков операций, где легко ошибиться и трудно повторять эксперимент. Пять скрытых нейронов оставляют вычисления обозримыми: их можно выписать на бумаге, проверить промежуточные суммы и последовательно набрать формулы на инженерном калькуляторе.
Обучение без NumPy как проверка понимания
Отказ от NumPy в обучающем коде не делает модель производительнее, зато делает её прозрачнее. Все операции приходится выразить явно: прямой проход, вычисление ошибки, обратное распространение, обновление весов. Для небольшой сети такой подход вполне реалистичен и полезен как учебная проверка.
В обычном проекте мы редко пишем такой код вручную. Фреймворк скрывает детали за слоями, оптимизаторами и тензорными операциями. Здесь же каждый коэффициент появляется как конкретное число, которое потом можно перенести в инференс. Это приближает эксперимент к embedded-подходу: сначала модель обучается в удобной среде, затем на целевое устройство уезжает только минимальный набор параметров и арифметика для их применения.
Для homelab и edge-сценариев это знакомая схема. Не обязательно запускать обучение на слабом устройстве. Часто достаточно обучить модель отдельно, зафиксировать веса, упростить вычисления и встроить инференс туда, где доступны только базовые операции.
Геометрическая задача: лемниската Бернулли
Целевая область задаётся уравнением лемнискаты Бернулли:
(x² + y²)² — 2a²(x² — y²) = 0В эксперименте используется значение a = sqrt(0.5), поэтому коэффициент 2a² фактически превращается в единицу. Модель должна по координатам точки оценить, находится ли она в пределах этой фигуры. Это не бизнес-задача классификации, а удобный полигон: данные можно генерировать программно, результат легко визуализировать, а ошибка хорошо понятна геометрически.
Для маленького перцептрона такая форма интереснее простой прямой или окружности. Лемниската имеет нелинейную границу, поэтому сеть с одним скрытым слоем действительно должна комбинировать несколько промежуточных признаков. При этом задача остаётся достаточно компактной, чтобы не требовать большой модели.
Что значит перенести инференс на непрограммируемый калькулятор
Непрограммируемый калькулятор не хранит модель как исполняемый код. Поэтому перенос сводится к инструкции: какие числа ввести, в каком порядке выполнить операции и как интерпретировать результат. По сути, калькулятор становится арифметическим сопроцессором, а пользователь — планировщиком вычислений.
Практически это означает несколько шагов:
- Обучить модель на Python и сохранить веса со смещениями.
- Округлить коэффициенты так, чтобы с ними было удобно работать вручную.
- Выписать формулы для пяти нейронов скрытого слоя.
- Посчитать их значения для конкретных
xиy. - Подставить результаты в формулу выходного нейрона.
- Сравнить итог с выбранным порогом классификации.
Главная сложность здесь не в самой математике, а в дисциплине вычислений. Чем больше ручных шагов, тем выше риск ошибки ввода. Поэтому для такой демонстрации важны компактная архитектура, стабильные коэффициенты и понятный критерий результата.
Точность 70–85% как инженерный компромисс
Заявленный минимально приемлемый диапазон вероятности — примерно 70–85%. Для демонстрационного проекта это честная цель. Маленькая сеть, ручной инференс и округление коэффициентов не должны соревноваться с полноценной численной моделью. Зато они показывают, какую полезную аппроксимацию можно получить из совсем небольшого количества параметров.
Такой уровень качества хорошо подходит для объяснения принципа: модель не знает уравнение фигуры напрямую, но учится приближать границу по примерам. Ошибки будут появляться около сложных участков границы и в точках, где округление весов меняет итоговое значение. Именно там лучше всего видно отличие между строгой аналитической проверкой и нейросетевой классификацией.
Чем это полезно вне эксперимента
Запуск перцептрона на калькуляторе не означает, что так стоит строить production-системы. Польза в другом: эксперимент снимает магию с маленьких нейросетей. После него проще обсуждать квантование, перенос моделей на микроконтроллеры, edge-инференс и ограничения слабого железа.
Для разработчика это хороший способ проверить несколько базовых навыков:
- понимать прямой проход без абстракций фреймворка;
- видеть связь между архитектурой и числом операций;
- оценивать влияние округления коэффициентов;
- отделять обучение модели от её применения;
- проектировать инференс под реальные ограничения устройства.
Такие упражнения особенно полезны перед работой с TinyML и embedded AI. Если модель можно вручную разложить до понятной последовательности арифметических действий, её проще оптимизировать, тестировать и переносить на ограниченные платформы.
Итог
Маленький перцептрон 2-5-1, обученный на чистом Python и перенесённый на инженерный калькулятор, — это не про производительность. Это про инженерную разборчивость. Модель становится набором конкретных чисел и операций, а инференс — воспроизводимой процедурой без скрытых слоёв инфраструктуры.
Именно поэтому подобные проекты ценны: они показывают, что даже современные идеи машинного обучения в минимальной форме остаются обычной математикой. А значит, их можно понять, проверить и при необходимости адаптировать под самые скромные вычислительные условия.
Читайте также
