 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Что меняется в Kafka, когда исчезает ZooKeeper
Apache Kafka долгое время ассоциировалась не только с брокерами и топиками, но и с обязательным ZooKeeper. Именно он хранил часть метаданных кластера, помогал выбирать контроллер, отслеживал состояние брокеров и участвовал в координации. Для эксплуатации это означало отдельный распределённый сервис, отдельные настройки, отдельный мониторинг и отдельный класс инцидентов.
KRaft меняет эту модель. Метаданные Kafka теперь управляются самой Kafka через встроенный кворум контроллеров. В результате архитектура становится проще для понимания и сопровождения: меньше внешних зависимостей, единый стек эксплуатации и более предсказуемый путь масштабирования.
Но KRaft — это не просто «Kafka без ZooKeeper». Это другая модель управления метаданными, в которой важно понимать роли узлов, требования к кворуму и последствия отказов.
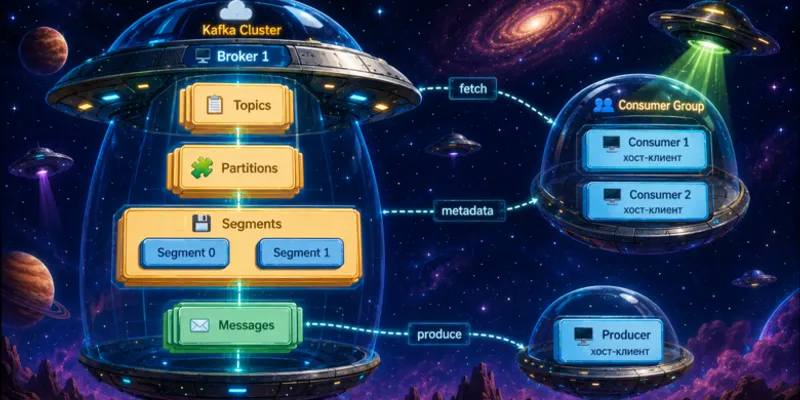
Из чего состоит современный кластер Kafka
В базовой модели Kafka остаются знакомые сущности:
- брокеры принимают подключения клиентов;
- топики разделены на партиции;
- партиции реплицируются между брокерами;
- у каждой партиции есть лидер и follower-реплики;
- продюсеры пишут сообщения в лидера партиции;
- консьюмеры читают данные из партиций и координируются через consumer groups.
KRaft добавляет важное разделение ролей. Узел Kafka может быть брокером, контроллером или совмещать обе роли. Брокеры отвечают за хранение и передачу пользовательских данных. Контроллеры отвечают за метаданные: состояние брокеров, топиков, партиций, лидеров и конфигураций.
В небольших стендах роли часто совмещают. В production-кластерах их обычно разделяют, чтобы нагрузка на потоковые данные не мешала управлению метаданными.
Что такое контроллеры KRaft
Контроллеры формируют кворум и используют журнал метаданных. Изменения состояния кластера записываются как события: создан топик, изменена конфигурация, брокер пропал, лидер партиции переехал. Такой журнал реплицируется между контроллерами.
Это похоже на внутренний control plane. Если раньше Kafka полагалась на ZooKeeper как на внешнюю систему координации, теперь control plane находится внутри Kafka и использует собственный механизм согласования.
Главное правило — контроллеров должно быть нечётное количество. Для небольшого production-кластера типичный вариант — три контроллера. Для более крупного или критичного окружения — пять. Один контроллер не даёт отказоустойчивости, два создают неудобную модель кворума, а слишком большое количество увеличивает стоимость согласования.
Почему кворум важнее количества серверов
Кворум отвечает на вопрос: сколько контроллеров должно быть доступно, чтобы кластер мог безопасно принимать изменения метаданных. Для трёх контроллеров нужно большинство — два. Для пяти — три.
Если кворум потерян, Kafka не может корректно управлять изменениями: создавать топики, выбирать новых лидеров, фиксировать изменения конфигурации. Данные на брокерах при этом физически могут оставаться на месте, но control plane становится недоступен для нормальной работы.
Поэтому контроллеры нельзя размещать как попало. Если три контроллера находятся на одной виртуализационной ноде, отказ этой ноды равен потере кворума. Для homelab это частая ловушка: сервис вроде распределённый, но все управляющие компоненты живут на одном физическом хосте.
Брокеры и репликация партиций
Брокеры в Kafka хранят сегменты логов. Топик делится на партиции, и каждая партиция имеет набор реплик. Одна реплика назначается лидером: через неё идут записи и, в большинстве сценариев, чтение. Остальные реплики догоняют лидера.
Отказоустойчивость задаётся несколькими параметрами:
- replication factor — сколько копий партиции хранить;
- min.insync.replicas — сколько синхронных реплик требуется для подтверждения записи;
- acks у продюсера — какого подтверждения ждёт клиент;
- стратегия размещения реплик по брокерам и стойкам.
Например, replication factor 3 сам по себе не гарантирует надёжность, если все три реплики оказались на одном физическом сервере или одном дисковом массиве. Как и в любой распределённой системе, важно думать не только о логической схеме, но и о доменах отказа.
Что меняется при эксплуатации
Переход на KRaft уменьшает количество компонентов, но повышает важность правильного понимания ролей Kafka. Теперь оператору нужно следить за двумя плоскостями внутри одного продукта:
- data plane: брокеры, диски, сеть, партиции, лаг реплик;
- control plane: контроллеры, кворум, журнал метаданных, выборы лидера контроллера.
Мониторинг должен явно показывать состояние кворума. Недостаточно видеть, что брокеры отвечают на клиентские запросы. Нужно понимать, живы ли контроллеры, есть ли большинство, нет ли задержек репликации метаданных и не слишком ли часто происходят выборы.
Также стоит отдельно отслеживать диски. Kafka чувствительна к latency и пропускной способности storage: брокер может быть формально доступен, но из-за медленного диска начнёт отставать по репликации и создавать проблемы для топиков с жёсткими требованиями к надёжности.
Практичная схема для небольшого кластера
Для малого production или серьёзного homelab можно начать с такой модели:
- три выделенных контроллера KRaft;
- минимум три брокера для пользовательских данных;
- replication factor 3 для критичных топиков;
- min.insync.replicas 2;
- acks=all у важных продюсеров;
- размещение контроллеров и брокеров по разным физическим узлам.
Если ресурсов мало, можно временно совмещать роли broker и controller. Но тогда нужно особенно внимательно смотреть на нагрузку: интенсивная запись в топики не должна приводить к нестабильности control plane.
Для тестового окружения допустимы упрощения, но важно не переносить их в production по привычке. Одна виртуальная машина с Kafka в режиме «всё в одном» полезна для разработки, но почти ничего не говорит о поведении настоящего кластера при отказах.
Что проверить перед запуском
Перед вводом Kafka с KRaft в эксплуатацию полезно пройти короткий чек-лист:
- контроллеров нечётное количество;
- кворум переживает потерю одного узла;
- контроллеры разнесены по физическим доменам отказа;
- брокеры имеют достаточно диска и сетевой пропускной способности;
- для критичных топиков настроены replication factor и min.insync.replicas;
- клиенты используют подходящие acks и retry-настройки;
- мониторинг показывает состояние контроллеров, брокеров, ISR и lag;
- есть процедура замены контроллера и брокера;
- бэкапы и DR-план учитывают не только данные, но и конфигурацию кластера.
Этот список кажется базовым, но именно такие вещи чаще всего отличают лабораторный запуск Kafka от устойчивой платформы сообщений.
Итог
KRaft делает Kafka проще как систему: меньше внешних зависимостей, единый control plane и более понятная эксплуатационная модель. Но простота не отменяет распределённую природу Kafka. Кворум контроллеров, размещение реплик, диски и сеть остаются критичными элементами архитектуры.
Если проектировать кластер с учётом доменов отказа и заранее наблюдать за состоянием control plane, Kafka с KRaft становится удобнее и надёжнее классической связки с ZooKeeper. Если же просто убрать ZooKeeper и оставить случайное размещение узлов, новая архитектура не спасёт от старых ошибок эксплуатации.
Читайте также
