 Трендовые github проекты в нашем телеграм канале. Подпишись →
Трендовые github проекты в нашем телеграм канале. Подпишись → Когда кластер есть, а отказоустойчивости всё ещё нет
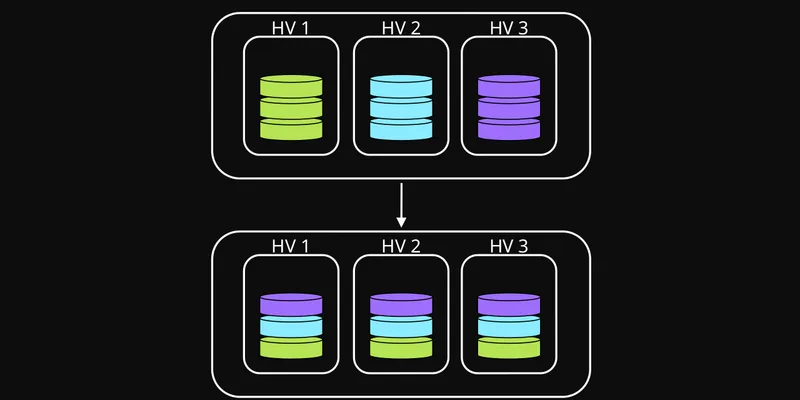
Кластер виртуализации часто воспринимают как готовую страховку от аварий: несколько физических узлов, общий пул ресурсов, миграция виртуальных машин и возможность пережить падение одного сервера. На практике этого недостаточно. Если критичные сервисы случайно оказались на одном хосте, отказ такого хоста всё равно превращается в простой целого контура.
Проблема особенно заметна в homelab, небольших офисных инсталляциях и внутренних платформах, где кластер уже появился, но правила размещения ещё не формализованы. Виртуальные машины создаются по мере необходимости, переносятся вручную, часть сервисов клонируется, часть объединяется в пары, а через несколько месяцев уже сложно быстро ответить на простой вопрос: что именно упадёт вместе с конкретным узлом?
Почему одного кластера мало
Виртуализация решает задачу абстрагирования нагрузки от железа. Она упрощает перенос ВМ, снапшоты, обслуживание узлов и восстановление после части инцидентов. Но она не гарантирует, что зависимые или резервирующие друг друга сервисы окажутся разнесены по разным доменам отказа.
Типичный пример — два экземпляра одного приложения или пара серверов базы данных. Формально резервирование есть. Но если обе ВМ размещены на одном физическом сервере, то при сбое питания, проблеме с RAM, дисковой подсистемой или сетевой картой резерв исчезает одновременно с основным экземпляром.
То же касается вспомогательных компонентов: DNS, reverse proxy, monitoring, брокеры сообщений, контроллеры домена, VPN-шлюзы. Они могут казаться второстепенными, пока не выяснится, что без них недоступны и остальные сервисы.
Что считать доменом отказа
Для маленького кластера доменом отказа чаще всего является физический хост. Для более зрелой инфраструктуры стоит смотреть шире:
- сервер или blade;
- стойка;
- PDU или линия питания;
- ToR-коммутатор;
- storage-полка или datastore;
- зона доступности;
- отдельный провайдер или площадка.
В homelab обычно достаточно начать с узлов и хранилищ. Если два сервиса зависят от одного NFS-сервера или одного дискового массива, разнесение по compute-нодам не спасёт от отказа storage. Поэтому карта размещения должна учитывать не только гипервизоры, но и общие зависимости.
Анти-аффинити как базовое правило
Главный инструмент — правила анти-аффинити. Они запрещают размещать определённые виртуальные машины на одном физическом узле. Для резервируемых сервисов это почти обязательная настройка.
Разносить стоит:
- реплики одного приложения;
- primary/secondary узлы БД;
- несколько DNS или DHCP-серверов;
- reverse proxy и балансировщики;
- элементы мониторинга и алертинга;
- управляющие сервисы, от которых зависит восстановление.
Важно не превращать правила в хаос. Если задать слишком много жёстких ограничений, планировщик может потерять возможность нормально балансировать нагрузку. Лучше начинать с критичных групп и явно документировать, почему эти ВМ нельзя держать вместе.
Аффинити тоже бывает полезной
Обратная задача — держать связанные сервисы рядом. Например, приложение и его кеш могут выигрывать от низкой сетевой задержки, а тестовые стенды удобнее перемещать как группу. Но аффинити нужно применять осторожно: она повышает локальность, но может увеличить blast radius.
Хорошая практика — разделять правила по смыслу:
- анти-аффинити для компонентов, которые должны переживать отказ друг друга;
- мягкая аффинити для сервисов, где локальность полезна, но не критична;
- отдельные ограничения для лицензий, GPU, быстрых дисков и специальных сетей.
Если платформа поддерживает soft-правила, для некритичных случаев лучше использовать именно их. Тогда кластер сможет нарушить предпочтение ради запуска ВМ, но вернётся к оптимальному размещению позже.
Как подойти к оптимизации распределения
Первый шаг — инвентаризация. Нужно собрать список ВМ, их роли, зависимости и критичность. Даже простая таблица уже помогает увидеть рискованные группы: две реплики на одном узле, все прокси на одном datastore, мониторинг рядом с единственным VPN.
Дальше можно присвоить сервисам веса. Например:
- критичные пользовательские сервисы;
- инфраструктурные компоненты;
- stateful-системы;
- тестовые и одноразовые ВМ;
- фоновые задачи, которые можно быстро поднять заново.
После этого задача превращается в оптимизацию: распределить нагрузки так, чтобы при потере любого одного узла оставалось как можно больше важных функций. При этом нельзя забывать про CPU, RAM, диски, сеть и ограничения миграции.
Проверка через сценарии отказа
Полезный способ проверить размещение — мысленно или автоматически выключать каждый узел и смотреть последствия. Для каждого сценария стоит ответить:
- какие ВМ недоступны;
- какие пользовательские функции ломаются;
- есть ли рабочая реплика;
- сохраняется ли доступ к управлению кластером;
- сможет ли мониторинг сообщить об аварии;
- хватит ли ресурсов для перезапуска ВМ на оставшихся узлах.
Такая проверка быстро показывает разницу между «у нас три сервера» и «сервис переживает отказ одного сервера». Если после потери узла исчезают и приложение, и база, и DNS, то кластер пока даёт удобство администрирования, но не полноценную отказоустойчивость.
Что автоматизировать в первую очередь
Ручная проверка работает только на малом масштабе. Как только ВМ становится больше нескольких десятков, нужна автоматизация: выгрузка размещения из API гипервизора, описание сервисных групп в YAML или Git, расчёт рисков и отчёт перед изменениями.
Минимальный полезный отчёт может включать:
- список групп, нарушающих анти-аффинити;
- узлы с концентрацией критичных сервисов;
- ВМ без указанной роли или владельца;
- сервисы с единственной репликой;
- зависимости от одного datastore или сетевого сегмента.
Такой отчёт удобно запускать перед обслуживанием узла. Он заранее покажет, какие сервисы стоит мигрировать и где резервирование существует только на бумаге.
Практический вывод
Отказоустойчивость кластера начинается не с количества узлов, а с понятной модели отказов. Нужно знать, какие компоненты должны переживать потерю хоста, какие зависимости у них общие и какие правила мешают случайно собрать все критичные ВМ в одном месте.
Для небольшого кластера достаточно трёх шагов: описать сервисные группы, включить анти-аффинити для критичных реплик и регулярно проверять сценарий отказа каждого узла. Это не заменяет бэкапы и мониторинг, но резко снижает вероятность ситуации, когда один физический сервер неожиданно становится единственной точкой отказа для половины инфраструктуры.
Читайте также
