
Виртуализация адаптивной Grid-разметки: как ускорить большие интерфейсы
Разбираем, как виртуализировать адаптивную CSS Grid-разметку: расчёт видимой области, динамические размеры, overscan и типичные ошибки производительности.
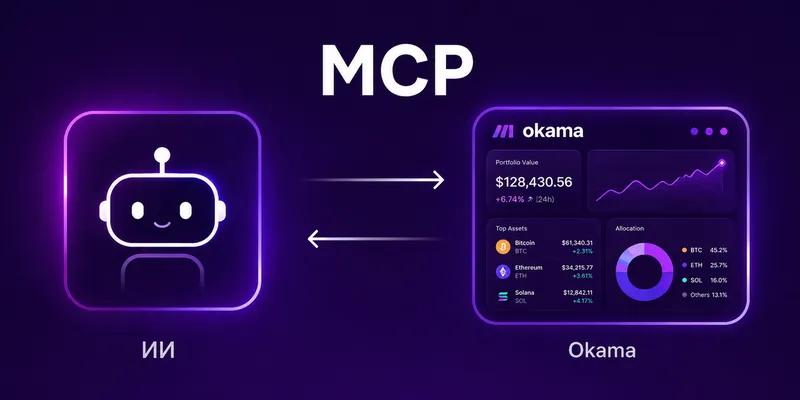
MCP для портфельной аналитики: как подключить AI-ассистента к данным
Model Context Protocol помогает безопасно связать LLM с портфельной аналитикой: данными, метриками, инструментами расчёта и понятными ограничениями доступа.

AI-ready дата-центр: почему инфраструктура для ИИ сложнее обычного ЦОДа
Разбираем, чем AI-ready дата-центр отличается от классического модульного ЦОДа: питание, охлаждение, сеть, плотность стоек и эксплуатация GPU-кластеров.
Надёжный AI-агент: инженерные принципы вместо магии
Разбираем, какие свойства делают AI-агента пригодным для production: контекст, инструменты, контроль действий, наблюдаемость, память и безопасная деградация.

Асинхронный пул соединений MySQL: как пережить всплеск трафика без лишней RAM
Разбираем, почему приложение падает на max_connections, как устроить connection pool и какие лимиты, таймауты и метрики нужны backend-сервису.
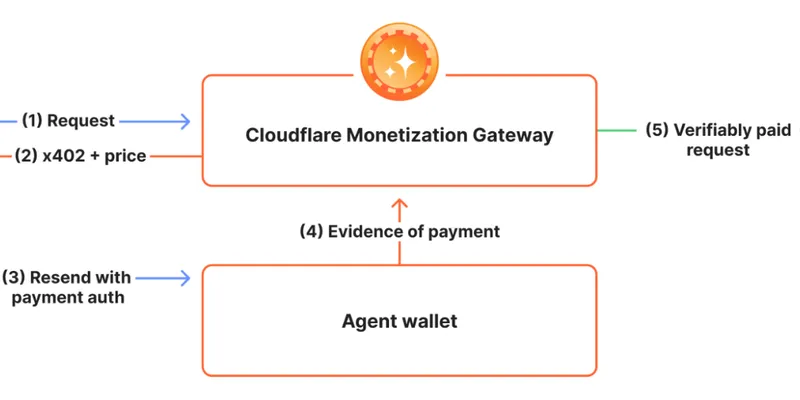
x402 и платный доступ к API: как может выглядеть монетизация без собственной платёжной системы
Разбираем идею Monetization Gateway: HTTP 402, оплата за API, датасеты и MCP-инструменты, риски авторизации, лимитов и эксплуатации.

KMS вместо ключей в конфиге: как выстроить управление секретами в облаке
Практический разбор роли Key Management Service: модели доверия, envelope encryption, ротация ключей, аудит и типовые ошибки интеграции.
AngaraBase и HTAP: зачем совмещать транзакции и аналитику в одной СУБД
Разбираем идею HTAP-СУБД с PostgreSQL-совместимым протоколом: MVCC без VACUUM, векторизованное исполнение, observability и практические риски внедрения.
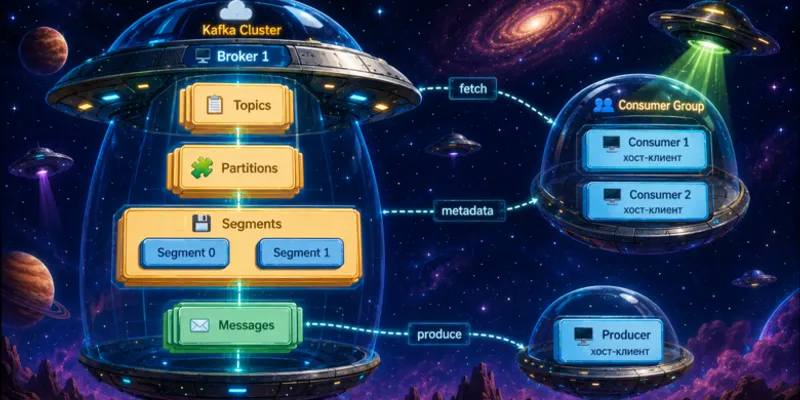
Kafka с KRaft: как устроен кластер без ZooKeeper
Разбираем, зачем Kafka перешла на KRaft, какие роли появились в кластере и что важно учитывать при проектировании брокеров, контроллеров и топиков.
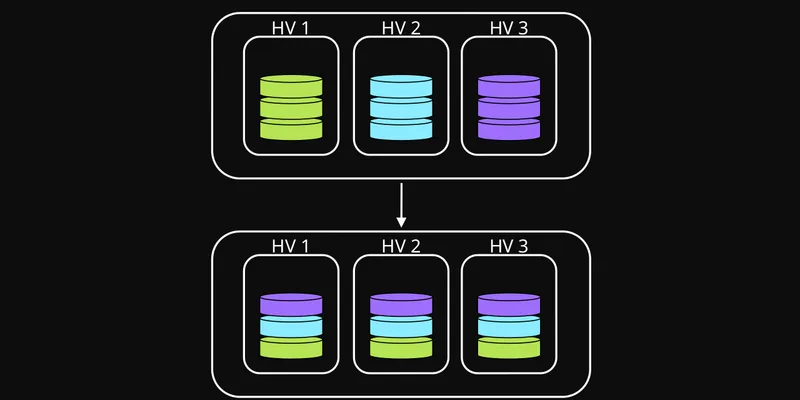
Отказоустойчивость сервисов в кластере виртуализации: как помогает грамотное распределение
Практический разбор того, как размещение сервисов по узлам кластера снижает риск общей аварии и делает homelab-инфраструктуру предсказуемее.
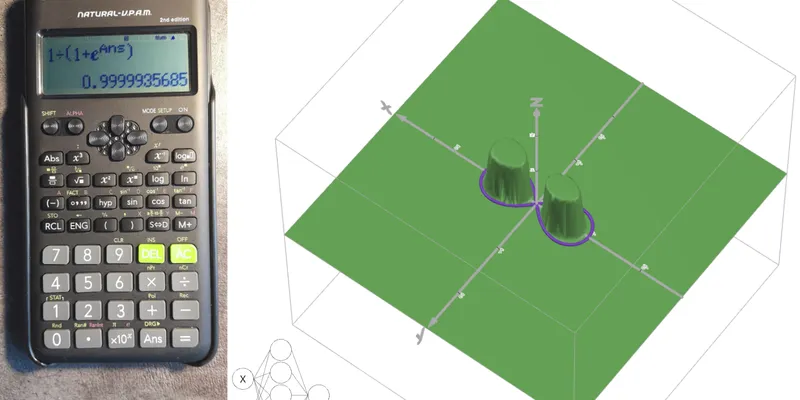
Перцептрон на непрограммируемом калькуляторе: что показывает такой эксперимент
Разбираем, как небольшой перцептрон 2-5-1 можно обучить на Python без NumPy и перенести инференс на обычный инженерный калькулятор Casio.

Трендовые уязвимости июня: как быстро расставить приоритеты
Практичный подход к разбору июньских уязвимостей: что проверять первым, как учитывать эксплуатацию, риск для инфраструктуры и готовность патчей.

FluxCD в GitOps: шесть практичных приёмов для Kubernetes
Как выжать больше пользы из FluxCD: зависимости, Helm и Kustomize, паузы, автоматизация образов, уведомления и безопасная организация репозиториев.

Лазерная передача энергии для космической инфраструктуры
Почему лазерная передача энергии снова стала практичной темой для спутников, орбитальных узлов и высотных платформ, и какие инженерные ограничения важны уже сейчас.
Вайб-кодинг: первый эксперимент без потери контроля
Практичный разбор того, как относиться к коду, сгенерированному нейросетью: где он ускоряет работу, где требует проверки и как встроить такой эксперимент в инженерный процесс.
Постоянные облачные среды для AI-агентов: зачем им нужен рабочий контекст
Почему долгоживущие cloud environments становятся важной частью агентной разработки: изоляция, безопасность, состояние, CI, наблюдаемость и правила эксплуатации.
Партнёрская сеть для enterprise AI: как масштабировать внедрение без хаоса
Что означает запуск крупной партнёрской программы для корпоративного ИИ: роли интеграторов, требования к платформе, безопасность, эксплуатация и метрики успеха.

Безопасность автомобильных сигнализаций как урок для IoT-инфраструктуры
Почему популярные охранные устройства стоит рассматривать как полноценные программно-аппаратные системы: модель угроз, обновления, раскрытие уязвимостей и практики эксплуатации.

Метрики внедрения AI: почему счётчик запросов не доказывает пользу
Как оценивать корпоративного AI-ассистента по удержанию, повторяемым сценариям и замещению старых процессов, а не по количеству разовых обращений.

Open source governance для цифровых реформ
Как выстроить управление открытым кодом в государственных и инфраструктурных проектах: роли, процессы, безопасность и устойчивость экосистемы.
LLM-инференс и специализированные чипы: что меняется в архитектуре AI-инфраструктуры
Как появление LLM-оптимизированных ускорителей влияет на задержки, стоимость инференса, планирование кластеров и эксплуатацию AI-сервисов.

Baseline для браузерных API: как безопасно переводить новые возможности в прод
Практический подход к оценке CSS, HTML, JavaScript и WebAPI через Baseline: что считать готовым к продакшену и как встроить это в процесс разработки.

Асинхронность в WebAssembly: что меняет WASI 0.3
Как WASI 0.3 переносит async на уровень Component Model, зачем нужны future и stream, и почему это важно для серверных WASM-компонентов.

Принципы безопасности пакетных репозиториев для supply chain
Как организовать защиту публичных и внутренних хранилищ артефактов: идентификация, публикация, зависимости, аудит и эксплуатационные практики.

PAD+ AI v4.0: когнитивная архитектура для наблюдаемых LLM-систем
Разбираем подход PAD+ AI v4.0: 22 фазы обработки, несколько типов памяти, эмоциональная модель и трассировка решений как инженерный слой поверх LLM.
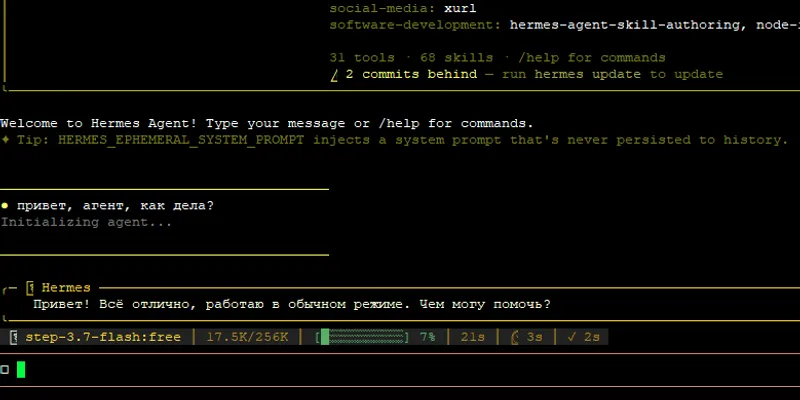
Hermes на VPS: зачем агенту память и навыки
Разбираем, чем автономный агент Hermes полезен на VPS, как относиться к его памяти, автонавыкам и рискам при работе на собственном сервере.

Point0: фулстек TypeScript-фреймворк на Bun и React
Разбираем, чем интересна идея фулстек-фреймворка на Bun и React, какие проблемы DX он пытается решить и на что смотреть перед использованием в реальном проекте.